DWH-Temporalität Teil 3: Zeitachsen ausgeben
In manchen Fällen ist die Ausgabe von Zeitachsen in Reports unerlässlich – etwa für Kundenhistorien, Betrugserkennung oder den Vergleich von Wissensständen.
Auch wenn es in vielen Fällen nicht notwendig ist, Zeitachsen in Reports auszugeben, gibt es Situationen, in denen die Ausgabe von Zeitachsen wichtig ist.
Beispiele sind:
-
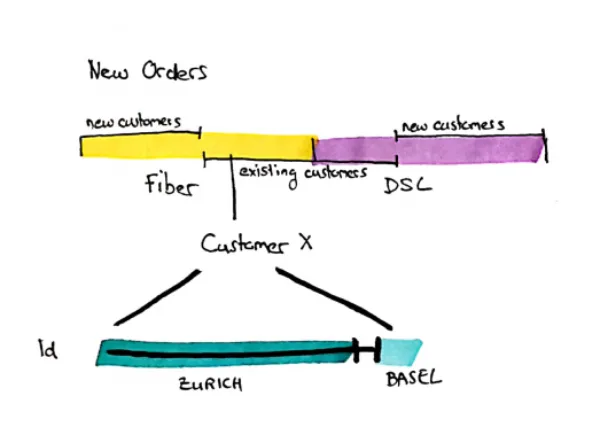
Darstellung einer Kundenhistorie (1d)
-
Hervorhebung nachträglich geänderter Daten zur Betrugserkennung und Erkennung legitimer Korrekturen (2d)
-
Flexibler Vergleich verschiedener Zeiträume zum Verständnis relativer Veränderungen (3d)
Falls Sie noch nichts über 1d (Business Validity), 2d (Inscription Time) und 3d (Load Time) gehört haben, empfehle ich, den ersten Teil dieser Serie zu lesen.
Ausgabe der 1d-Zeitachse: Beispiel Kundenhistorie
In Reports, die aggregierte Werte zeigen, möchte man manchmal bis auf einen Einzelfall herunterzoomen. Um diesen Fall zu verstehen, möchten wir vielleicht die Historie eines Kunden nachvollziehen: Wann lebte er in welcher Region und wann hat er welche Abonnements geändert? Ein Beispiel könnte sein, dass wir sehen, dass bestehende Kunden ihren DSL-Internetanschluss kündigen, aber später Glasfaser bestellen. Um zu verstehen, was passiert ist, könnte es nützlich sein, einige Stichproben herauszugreifen, zu analysieren und neue Business Rules zu erstellen, um solche Use Cases später auch auf aggregierter Ebene zu verstehen.
Das ist eine 1d-Historie: die fachliche Gültigkeit.
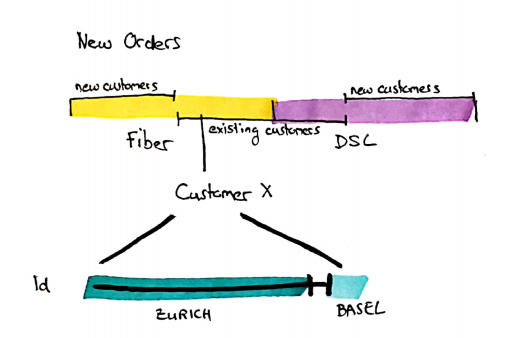
Wie wir bereits in Teil 2 dieser Artikelserie gelernt haben, kann man dies in einem Temporal Instance Hub speichern, indem das Valid From-Datum zum Business Key hinzugefügt wird. Da die Granularität des Hubs und der auszugebenden Daten nun übereinstimmen, muss ich keine Änderungen an der Ausgabe vornehmen. Das Einzige, was ich berücksichtigen muss: Eine Verschiebung eines Time Slices auf der 1d-Zeitachse im Quellsystem (Änderung der Valid From-Zeit) wird vom DWH als ein gelöschter und ein neuer Time Slice erkannt, da die Valid From-Zeit Teil unseres Schlüssels ist.
Das bedeutet, dass wir die nicht mehr gültige Version eines Time Slices markieren oder herausfiltern müssen.
Dies erreichen wir, indem wir in einem Tracking Satellite festhalten, ob ein Schlüssel noch in der Quelle vorhanden ist oder nicht. Wichtig: Das funktioniert nur mit Full Loads. Das ist unabhängig vom Datavault Builder und sogar unabhängig von Data Vault. Wenn ich keine explizite Delete-Meldung aus der Quelle erhalte, kann ich als Empfänger implizit gelöschte Zeilen nur durch einen Full Load erkennen.
Dieser Full Load muss jedoch nur alle Teile des Business Keys enthalten – nicht alle Attribute. Es ist daher möglich, die Attribute als Delta zu laden und nur den Schlüssel und die Valid From-Zeit vollständig zu laden, um solche „Löschungen" zu erkennen.
Wenn ich diese Zeilen nun im Report ausgebe, verknüpfe ich den Tracking Satellite und filtere entweder alle Zeilen heraus, die nicht mehr in der Quelle vorhanden sind – im DWH selbst –, oder markiere sie zumindest auf der Schnittstelle zu den Reports als gelöscht und implementiere einen vorausgewählten Filter im Report.
![]()
Da die Erstellung der entsprechenden Tracking Satellites sowie die Ausgabe als virtuelles Feld im Datavault Builder automatisiert ist, werde ich hier nicht im Detail darauf eingehen. Wer jedoch einen solchen Full Load Tracking Satellite selbst implementieren möchte, muss nur die BKs (technisch funktioniert auch der Hash davon) mit dem Hub vergleichen und die beiden Datensätze schneiden: Business Keys, die im Hub vorhanden sind, aber nicht in der Staging-Tabelle, müssen als FALSE markiert werden – alle anderen als TRUE.
Alternative Methoden zur Erkennung von Änderungen in Time Slices
Wenn das Quellsystem zumindest zuverlässig echte Löschungen liefert (also nicht nur Verschiebungen, die wir als Löschungen wahrnehmen), kann man auch eine CDC mit Hilfe einer Persistent Staging Area (PSA) aufbauen.
Ich beziehe mich auf eine PSA, die eine SCD Type 2-Historie auf der 3d-Zeitachse basierend auf technischen Schlüsseln erstellt – und nicht auf eine vollständige Snapshot-PSA.
Wenn Time Slices im Quellsystem mit demselben technischen Schlüssel erfasst werden, können wir erkennen, dass es sich um eine Änderung und nicht um ein Delete & Insert handelt:
Basierend auf diesen Informationen können wir mit einem „Partition By" BK auf dem Satellite – in diesem Fall den aus der Quelle übernommenen technischen Schlüssel – immer nur den letzten Eintrag auswählen, um nur die relevante Information zu erhalten.
Diese kann dann in einem neuen Hub und Satellite Kunde gespeichert oder einfach virtualisiert ausgegeben werden. In jedem Fall sollte die 3d-Zeitachse durch einen as-now-Schnitt reduziert werden, bevor die Daten jemand anderem zur Verfügung gestellt werden. Das bedeutet, dass die 1d-Zeitachse ausgegeben wird, aber nur mit dem aktuellen Status gemäß der 3d-Zeitachse.
Mir ist es wichtig, auf die inhärente Eleganz dieses Ansatzes hinzuweisen: Im Gegensatz zu anderen Varianten müssen Sie nicht einmal Surrogate Keys berechnen. Die einzelnen Einträge werden eindeutig durch BK + Valid From oder stellvertretend durch den entsprechenden Hash dargestellt – und alle Referenzen sind bereits auf dieser Granularität vorbereitet. Keine Lookups. Keine unschönen Zwischen-Joins. Die Daten einfach ausgeben.
2d-Zeitachse: Betrugserkennung
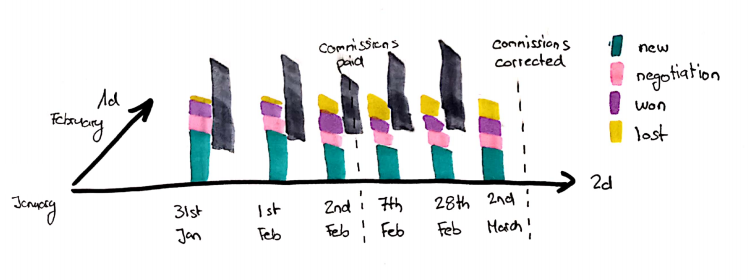
Vor einigen Jahren wurde ich gebeten, einige Unregelmäßigkeiten bei der Vertriebsprovisionierung eines Kunden zu untersuchen. Es gab verschiedene Regeln, wann ein Vertriebsmitarbeiter Anspruch auf eine Verkaufsprovision hatte. Am ersten Tag jedes Monats wurde geprüft, wie viele neue Verträge ein Vertriebsmitarbeiter abgeschlossen hatte. Die Lieferung und Rechnungsstellung des Produkts war manchmal recht schnell, aber da bestimmte Produkte nicht auf Lager waren, war eine Lieferung erst 2–3 Wochen später möglich – was die Rechnungsstellung verzögerte.
Einige Verkäufer nutzten dies, um Verträge am letzten Tag eines Monats zu erfassen und sie am Tag nach der Provisionsberechnung rückwirkend zu stornieren.
Bei einem einzelnen Kaufauftrag sah es so aus, als hätte der Verkäufer den Vertrag erfasst und am selben Tag gelöscht. Das war ein völlig normales Szenario, da nach der Erfassung der Verträge ein Bestätigungsschritt folgte, bei dem alles dem Kunden noch einmal vorgelesen wurde und dem er zustimmen musste.
Für Provisionen wurden die Verträge jedoch gezählt. Wenn derselbe Report 2 Tage später erstellt wurde, sah er völlig anders aus und identifizierte die entsprechenden Vertriebsmitarbeiter klar. Aber wenn Betrug der einzige Grund für dieses Muster gewesen wäre, hätte man die entsprechenden Verkäufer einfach entlassen können. Der Punkt ist jedoch, dass solche Geschäftsprozesse teilweise legitim sein können (z. B. ein 2-wöchiges Rücktrittsrecht in bestimmten Märkten).
Was sind mögliche Lösungen für dieses Problem: Wenn das Quellsystem jede Änderung mit der Inscription Time aufzeichnet, können Sie diese verwenden, um die Historie nachzuvollziehen. Bei einem Betrugsmuster, das auch zwischen zwei DWH-Loads auftritt, wäre das die einzige Möglichkeit.
In diesem Fall mussten die Verkäufer jedoch warten, bis die Daten in den Data Mart übertragen worden waren. Dies hätte es ermöglicht, das Betrugsmuster klar auf der 3d-Zeitachse zu dokumentieren, wäre aber für die Verkäufer, die keinen Betrug begingen und ihre Provisionszahlen überprüfen mussten, weniger genau und schwerer verständlich gewesen.
Fall 1: 2d-Zeit im Quellsystem gespeichert, aber ohne Historie
Wie gehe ich also mit diesen Daten um? Wenn das Quellsystem die Inscription Time aufzeichnet, aber keine Historie jeder Änderung führt, muss ich das Wissen über die 2d-Historie mithilfe der 3d-Historie im DWH erzeugen. Wie bereits im zweiten Teil dieses Artikels erklärt, ist eine 3d-Historie in einem solchen Fall nur eine Näherung – und umso besser, je häufiger die Loads ins DWH stattfinden. Bei intraday Loads oder sogar Streaming Loads kann es am Ende fast eine perfekte Näherung werden.
Beispiel:
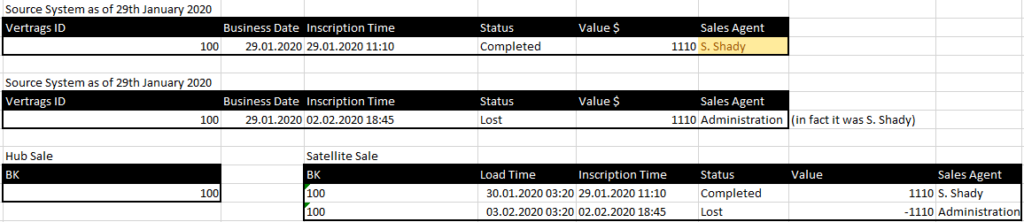
Ein Vertrag ändert sich am 29. Januar 2020 (Inscription Date) vom Status Angebot zu Abgeschlossen. Die fachliche Gültigkeit ist ebenfalls der 29. Januar 2020.
Derselbe Vertrag ändert sich am 2. Februar (Inscription Date) von Abgeschlossen zu Verloren.
Ich kann also einen Hub mit einem Satellite erstellen, bei dem der Hub-BK entweder nur den Business Key des Vertrags enthält oder – bei einer 1d-Historie im Quellsystem – den Business Key plus die Valid From-Zeit. Das ist völlig unabhängig.
Wir empfehlen, die 2d-Zeiten einfach als Satellite-Attribute zu speichern. Das bedeutet, dass Sie zum Zeitpunkt der Datenspeicherung nicht alle Business Rules zur Ausgabe verstehen müssen. Das ist übrigens ein großer Paradigmenwechsel im Data Vault gegenüber dem Inmon 3NF Warehousing.
Der Unterschied ist, dass ich nicht nur auf die letzten Daten auf der 3d-Historie (as-now) zugreifen kann, sondern die Zeitachse auf der 3d-Timeline auswerten muss, um die 2d-Timeline zu rekonstruieren.
Eine Idee wäre, die Satellite-Daten mit 3d-Historie in die Reports auszugeben. Technisch korrekt, aber wahrscheinlich wenig hilfreich. Denn dann muss ich die entsprechende Logik in die Reports einbauen, um zu rekonstruieren, was tatsächlich passiert ist.
Was mich eigentlich interessiert: einerseits der Abschluss von Verträgen und die Auflösung dieser Verträge auf einer unveränderlichen Zeitachse.
Da angenommen wird, dass in diesem Fall Änderungen rückwirkend auf der 1d-Zeitachse eingetragen werden können, verwenden wir die 2d-Zeitachse für unsere Auswertung. Und wir können Ereignisse aus der Änderung von Attributen ableiten – hier primär am Vertragsstatus –, auf dieser Zeitachse:
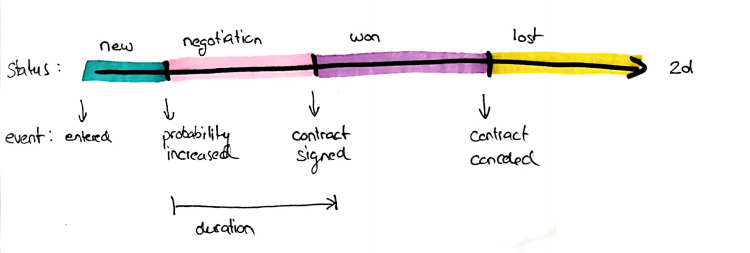
In der folgenden Ausgabe haben wir bereits die erste Regel implementiert, dass der Wert für das Ereignis „Verloren" negativ wird. Aber wir sehen bereits hier, dass S. Shady clever war. Er hat hier den Verkaufsagenten geändert, damit das Stornierungsereignis nicht ihm zugerechnet wird.

Wir führen also eine neue Regel ein, die den Sales Agent aus dem letzten „Abgeschlossen"-Ereignis übernimmt:

Und dann werden die Umsätze von S. Shady im Februar um den verlorenen Vertrag reduziert. Das wiederum funktioniert nur bei linearen Verkaufsprovisionen. Andernfalls muss der Zeitraum abgeleitet werden, für den die Korrektur gilt:
![]()
Und spätestens hier sehen Sie: Die Anforderung, die Daten einfach in SCD Type 2-Form auszugeben, wie sie im Satellite auf der 3d-Achse gespeichert sind, hilft niemandem. Erst durch die Interpretation der Ereignisse auf den verschiedenen Zeitachsen entsteht verwertbares Wissen. Mit den wie oben aufbereiteten Daten muss ich im Report nur noch nach der Inscription Time aggregieren. Außerdem kann ich die Correction Time verwenden, um zu verstehen, was sich seit meiner letzten Analyse geändert hat.
Ich stimme Michael Müller zu, wenn er feststellt: Je komplexer diese Anforderungen werden, je mehr Business Rules das Business definiert, um Attribute auf der Zeitachse zu korrigieren, desto besser ist man beraten, die gesamte Logik in ein Business Rule-Modul zu packen und eine sehr einfache Historie zu haben. Aber ohne fachliche Anforderungen können wir nur die Rohdaten weitergeben, und die Ableitung des Wissens muss im Report erfolgen. Und die mir bekannten Reporting-Tools sind nicht gut geeignet, um Zeilenübergreifende Analysen durchzuführen.
Es ist wichtig zu verstehen: Indem wir die 2d-Zeitstempel im Satellite mit 3d-Historie speichern, können wir später alle möglichen Sichten und Interpretationen durch die korrekte Abfragelogik ableiten. Daher gilt die empfohlene Vorgehensweise aus Teil 2 des Blogs weiterhin:
*** 1. Vereinfachung / Strategie: die 2d-Zeiten als normales Satellite-Attribut speichern***
Mit dem Zusatz: Wenn die 2d für die Analyse der Daten relevant ist, kann dies jederzeit bei der Ausgabe durch Interpretation der 3d-Historie erfolgen.
Fall 2: 2d-Zeit mit Historie im Quellsystem gespeichert, keine 1d-Historie
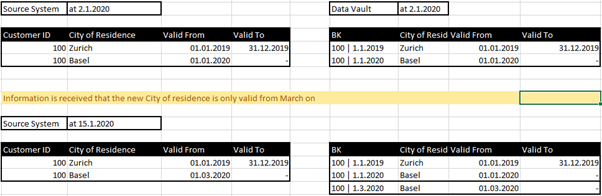
Wenn wir bereits eine 2d-Historie aus dem Quellsystem erhalten, ist unsere Quelldaten eine bereits historisierte Tabelle.
Wenn das Quellsystem nun eine 2d-Historie enthält, aber keine 1d-Historie, kann davon ausgegangen werden, dass die 2d-Historie mit der 1d-Historie gleichgesetzt werden kann, da sie wahrscheinlich die beste Näherung ist. Das bedeutet, dass angenommen wird, dass sich bestimmte Informationen im Laufe der Zeit ändern, die zu diesem Zeitpunkt gültige Information aber noch relevant ist. Im Gegensatz zu einer vollständigen nativen 1d-Historie können jedoch keine rückwirkenden oder zukünftigen Änderungen erfasst werden.
Wo findet man einen solchen Fall: möglicherweise in Quellsystemen, die keine 1d-Historie aufzeichnen können, bei denen aber Trigger in der Datenbank erstellt wurden, um die überschriebene oder aktuelle Version des Datensatzes zur Inscription Time in eine Historientabelle zu schreiben.
Einige Datenbanken haben dieses Konzept standardmäßig implementiert. Wie „system-versioned temporal tables" in MSSQL oder „temporal table" in Teradata. Nicht zu verwechseln mit Oracles Flashback Archive oder Snowflakes Time Travel. Im ersten Fall mit MSSQL und Teradata ist die Inscription Time als einzelne Spalte verfügbar. Im zweiten Fall bei Oracle und Snowflake können Abfragen sehr einfach as-then ausgeführt werden, aber jeweils nur für einen einzelnen Time Slice.
Wenn eine 2d-Historie als Näherung für die 1d-Historie verwendet wird, kann sie wie eine 1d-Historie behandelt werden.
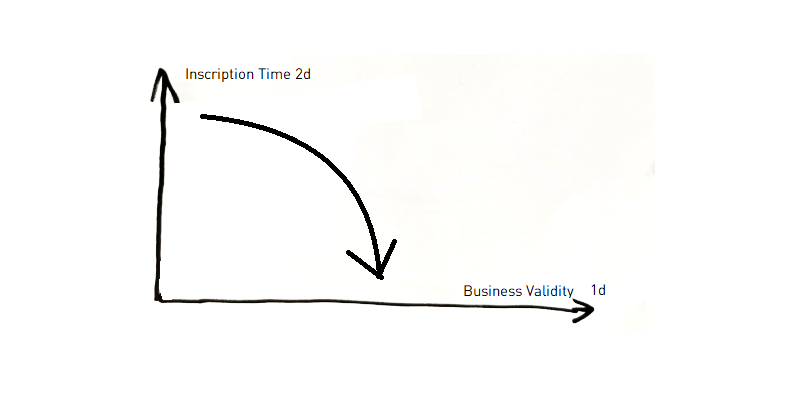
Es gilt daher aus dem zweiten Artikel:
*** 2. „Vereinfachung" / Strategie: einen Temporal Instance Hub erstellen,*** *** indem der Business Key mit der fachlich gültigen From-Zeit konkateniert wird***
Wie die 1d-Historie ausgegeben werden kann, ist im ersten Kapitel dieses Artikels zu sehen.
Fall 3: 2d-Zeit mit Historie im Quellsystem gespeichert, kombiniert mit 1d-Historie
Wenn wir bereits eine bi-temporale Datenquelle mit 1d- und 2d-Historie haben, befinden wir uns wahrscheinlich bei einem Versicherungsunternehmen. Für alle anderen Leser: Sie können dieses Kapitel glücklicherweise überspringen.
Für unsere Freunde des anspruchsvollen Versicherungsgeschäfts:
Es gibt zwei Möglichkeiten, solche Quelldaten in den Data Vault zu laden.
-
Kombination des Business Keys mit dem 1d Valid From-Zeitstempel und zusätzlicher Speicherung des 2d-Zeitstempels
-
Übernahme des technischen Schlüssels der Quelle und Speicherung als Persistent Staging Load (PSA Load)
Warum können wir in diesem Fall den 2d-Zeitstempel nicht einfach als Attribut im Satellite speichern? Weil die Granularität nicht stimmt: Wir erhalten nicht nur einen Datensatz für BK + Valid From-Zeit zu einem bestimmten Zeitpunkt, sondern mehrere, wenn es eine Korrektur für diesen 1d-Time Slice gab.
Lösung 1 wäre die bevorzugte Lösung aus Data Vault-Sicht, da sie auf signifikanten Schlüsseln basiert. Meine persönliche Erfahrung ist: Nehmen Sie Option 2. Irgendwie schaffen es Quellsysteme immer, mehr als einen Datensatz für denselben Eintrag auf der 1d- und 2d-Timeline zu erzeugen. Das geht zurück auf das Kapitel: Niemals einem Quellsystem vertrauen :)
Aus diesem Hub mit 2 Historien kann durch eine Business Rule, die nur den neuesten Datensatz auf der 2d-Timeline auswählt (= as-now-Schnitt auf der 2d-Achse in einem Business Vault Load), ein neuer Hub mit einer exklusiven 1d-Historie im Hub-Schlüssel und der 2d-Historie im Satellite als Attribut abgeleitet werden. Damit haben wir ein neues Muster auf ein bekanntes Muster reduziert. Für alles andere gilt das oben Gesagte.
Variantendiskussion
Mit diesem Muster können Sie nun einen Zeiger zwischen dem Hub mit nur 1d-Historie und dem Hub mit 1d- und 2d-Historie setzen, der auf den aktuellen Eintrag im zweiten verweist. Es ist daher nicht notwendig, die Attribute vom 1d- und 2d-Hub in den 1d-Hub zu kopieren.
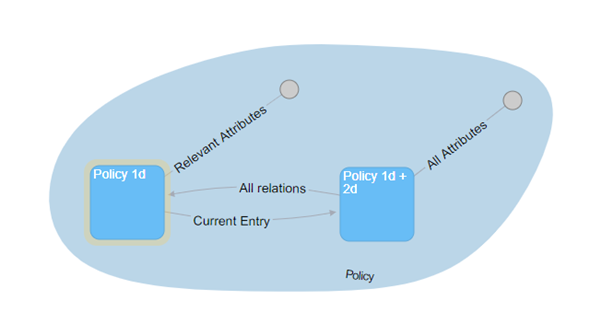
Oben ist ein Beispiel, bei dem im PSA Load der Hub „Policy 1d + 2d" direkt aus dem Quellsystem geladen wird und alle Attribute basierend auf dem technischen Schlüssel historisiert werden. Auch der Hub „Policy 1d" kann bereits mit den Schlüsseln befüllt werden (Distinct Load). Ein „All Relations"-Link könnte ebenfalls direkt aus der Quelle befüllt werden. Das macht Sinn, wenn z. B. die „1d & 2d" mit Anreicherungen auf einer DWH-Schnittstelle für Betrugsanalysen oder Process Mining bereitgestellt werden sollen. In einem solchen Fall empfehle ich, einen as-now-Schnitt auf der 3d-Timeline vorzunehmen, da selbst 2 Zeitachsen in einem Report sehr schwer zu verstehen sind.
Ein Business Vault Load filtert dann auf den letzten gültigen Eintrag pro 2d-Timeline und befüllt entweder nur den Link Current Entry, der die „Policy 1d"-Seite als treibende Seite konfiguriert hat, oder kopiert sogar bestimmte relevante Attribute und hängt sie direkt an den „Policy 1d"-Hub. Bei der zweiten Variante erzeugt die 3d-Historisierung im Satellite eine 2d-Timeline, die als Attribut gespeichert wird (ab dem Zeitpunkt, zu dem der Satellite geladen wird).
Mit dieser Modellierung kann ich nun alle möglichen Varianten für die Ausgabe an Datenempfänger wählen.
Ausgabe der 3d-Zeitachse: Wissenstände reproduzieren und vergleichen
Ein häufig genannter Fall für die Ausgabe der 3d-Zeitachse ist die Reproduzierbarkeit von Reports. Das ist eine sehr wichtige Anforderung, wenn z. B. Reports, die aus rechtlichen Gründen erstellt wurden, jederzeit reproduziert werden müssen. Sei es für Sarbanes-Oxley, Basel I, II oder III oder wie auch immer die entsprechenden Reports heißen mögen.
Diese Anforderung ist absolut real, kann aber manchmal in bestimmten Datenbanken mit Hausmitteln gelöst werden. Oracle bietet das Flashback Archive für solche Abfragen zu einem bestimmten Zeitpunkt an. Snowflake bietet mit Time Travel eine ähnliche Funktion – mit dem Unterschied, dass man dafür keine Organe verkaufen muss.
Bei Snowflake reicht ein einfaches SELECT x,y,z FROM a,b,c AT [TIMESTAMP]. Das funktioniert derzeit für 90 Tage in der Enterprise Edition, andernfalls nur 1 Tag. Es besteht auch die Möglichkeit, bestimmte Zeiträume auf der 3D-Achse mit CLONE AT als neue Datenbank zu speichern. Dabei werden nur die Zeiger auf die Daten kopiert, und man muss nicht erneut für die vollständige Datenbank bezahlen.
Wissenstände reproduzieren
Eine weitere einfache Variante ist die Verwendung von Reporting-Tools, die Daten in ihre eigene Struktur einlesen – wie QlikView / Qlik Sense –, um die so erstellten Reports zu speichern. Da solche Reports neben den üblicherweise einzureichenden Aggregaten auch Detaildaten enthalten können, kann dies die Anforderungen an die Reproduktion zu einem Stichtag hinreichend erfüllen.
Der Unterschied besteht darin, dass die Datenbankvariante Vergleiche zwischen zwei verschiedenen Zeiträumen ermöglicht, die Lösung mit gespeicherten Reports hingegen nicht (es sei denn, ich importiere sie erneut in eine Datenbank).
Die Lösung entspricht dem immer wieder beschriebenen Vorgehen: Einen Schnitt auf der 3d-Achse als as-now-Sicht vornehmen und diese Sicht dann speichern.
Wissenstände vergleichen
Aber möchte ich einem Report die Möglichkeit geben, den Wissensstand eines jeden Tages abzurufen und 2 oder mehr Wissenstände zu vergleichen?
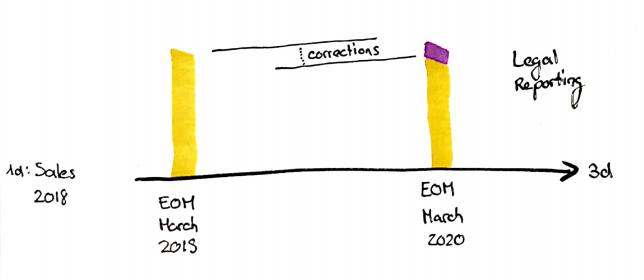
Wenn Sie die Anforderung des Business-Anwenders verstehen und seine Sichtweise teilen – oder wenn Sie hierarchisch dem Auftraggeber unterstellt sind –, müssen Sie einen SCD Type 2-Output für die 3d-Zeitachse erstellen. Die technische Umsetzung beschreibe ich im vierten Teil dieser Serie.
Epilog
Meine persönliche Meinung:
Im nächsten Artikel werde ich mich endlich damit befassen, wie man technisch einen SCD Type 2-Output für die 3d-Zeitachse erstellt. Was mir in dem gesamten Kontext bis zu diesem Punkt wichtig war, ist zu zeigen, dass dies in den meisten Unternehmen eher die Ausnahme als die Regel sein sollte – wenn überhaupt ein Bedarf besteht.
Wenn Sie SCD Type 2 für die 3d-Timeline als Standard einsetzen, tun Sie das wahrscheinlich, weil Sie es können – und weil niemand die Bedürfnisse der Business-Anwender ordentlich erhoben und/oder analysiert hat.
Natürlich kann auch Ralph Kimball eine Rolle spielen, der dies als Standardmuster für seine Data Marts beschrieben hat. Oder auch die vielen anderen Autoren, die die Erstellung von PIT-Tabellen technisch absolut korrekt beschreiben – unter der Annahme, dass man weiß, wann man sie verwenden sollte.
All diese Texte sind auch vollkommen korrekt. Aber wenn ich die Daten in einem solchen Format in die Reports schicke, ohne dass eine technische Anforderung dies rechtfertigt, mache ich sie unnötig kompliziert und mache Self-Service BI zu etwas zwischen schwierig und unmöglich.