DWH-Temporalität Teil 2: Komplexität
Wie sich temporale Komplexität im Data Vault reduzieren lässt – Datavault Builder-Nutzer fragen häufig, wie Änderungen über die Zeit korrekt abgebildet werden.
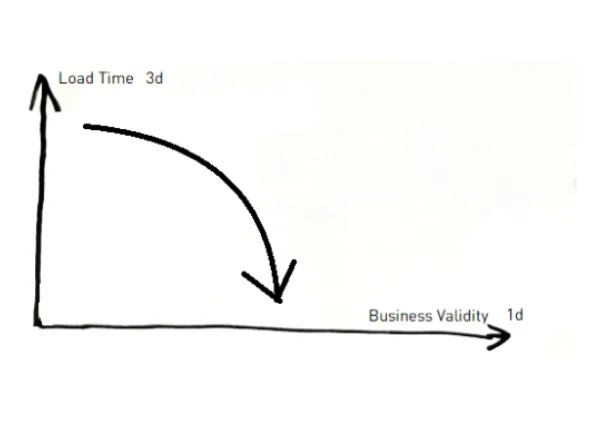
Über „Temporalität" im Data Vault
Die temporale Komplexität in den Griff bekommen
Als Hersteller der Datavault Builder-Automatisierungssoftware werden wir häufig gefragt, wie sich Änderungen über die Zeit in unserem Tool und/oder im Data Vault allgemein abbilden lassen. Oft in der Form: Wie kann ich SCD Type 2-Daten reporten? Dabei ist manchmal nicht klar, über welche Zeitachse wir eigentlich sprechen. Deshalb hier ein Versuch, das zu klären.
Dies ist der zweite Artikel in einer dreiteiligen Serie.
-
Der erste Artikel hat die Herausforderung der Temporalität im DWH definiert
-
Dieser Artikel definiert Möglichkeiten zur Vereinfachung der temporalen Komplexität, sofern möglich
-
Der dritte Artikel diskutiert fachliche Anforderungen zur Ausgabe von Zeitachsen
-
Der vierte Artikel erklärt, wie die 3d-Zeitachse technisch als SCD Type 2 ausgegeben wird
Es gibt verschiedene Ansätze zur Temporalität im Data Vault. Ich empfehle daher, die Texte von Dirk Lerner, Christian Kaul und Lars Rönnbäck zu lesen. Ich stelle hier eine Variante vor, wie die verschiedenen Zeitachsen so dargestellt oder vereinfacht werden können, dass sie beherrschbar werden. Ich werde auch einen Folgeartikel veröffentlichen, was zu tun ist, wenn eine solche Vereinfachung nicht möglich ist, weil die fachlichen Anforderungen mehr Optionen erfordern.
Wie im ersten Artikel definiert, diskutiere ich nur 3 Zeitachsen und verwende folgende Kurzbezeichnungen:
-
1d für Valid Time
-
2d für Inscription Time
-
3d für Load Time
Die erste Dimension (1d) ist die fachliche Gültigkeit. Diese Zeitachse ist insofern besonders, als ein neuer Time Slice auf der Zeitachse nicht bedeutet, dass der alte Eintrag ungültig ist: Wenn ich in Basel statt in Zürich wohne, ist die Information, dass ich einmal in Zürich gelebt habe, nicht falsch *1. Wenn ich einen zukünftigen Wohnort angebe, wird nicht einmal die Information über den aktuell gültigen Wohnort geändert. Wir haben also verschiedene Informationen, die zu verschiedenen Zeiten aktuell waren, aber alle noch korrekt und damit gültig sind.
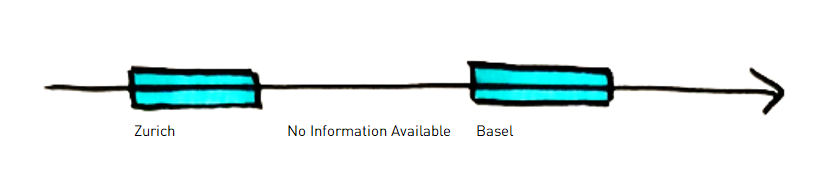
1d-Achse: Alle Informationen sind gültig, aber nur ein Eintrag ist aktuell.
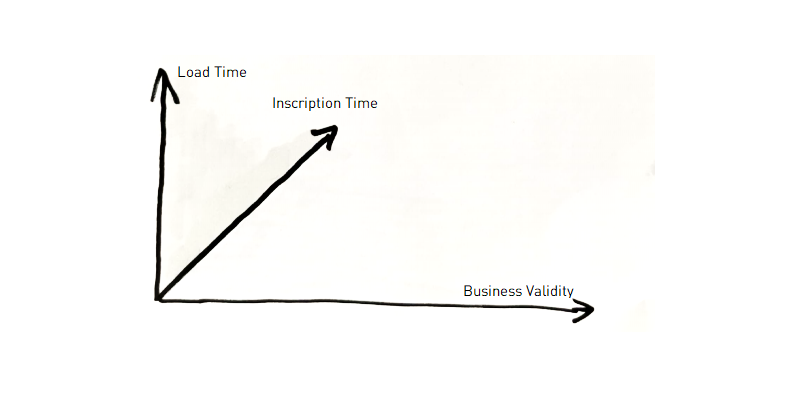
Die zweite Dimension (2d) ist die Inscription Time im Quellsystem. Sie ist relevant, weil auf der 1d-Achse auch neue Einträge für die Zukunft sowie Korrekturen für den aktuellen Time Slice und/oder die Vergangenheit erfasst werden können. In bestimmten Branchen und Abteilungen kann dies für Betrug genutzt werden. Als Beispiel: Verkaufsprovisionen können erschlichen werden, indem Verträge, die nicht wirklich existieren, erfasst und nachträglich gelöscht werden. Damit kann diese Zeitachse für Audit und Betrugsprävention entscheidend sein. Für normale Reportings kann sie oft vernachlässigt werden – insbesondere wenn die dritte Zeitachse nicht weit von dieser zweiten entfernt ist (z. B. durch tägliche oder sogar intraday Loads). Und das ist auch der Grund für die erste Vereinfachung: Ich schlage vor, die 2d-Zeitachse in einem Satellite zunächst einfach als Attribut zu speichern, damit keine Information verloren geht und später bei Bedarf spezielle Analysen möglich sind. In diesem Text gehe ich auf diesen Fall jedoch nicht explizit ein.
*** 1. Vereinfachung / Strategie: die 2d-Zeiten als normales Satellite-Attribut speichern***
Das bedeutet, dass wir aus dem dreidimensionalen Raum nur eine zweidimensionale Ebene betrachten:
Die dritte Dimension (3d) ist der Zeitpunkt, zu dem die Information in das Data Warehouse geladen wurde. Es gibt noch verschiedene Nuancen, ob man den Zeitpunkt erfasst, wenn die Daten ins Staging oder in den Core geladen werden, und ob man einen Zeitpunkt für den gesamten Batch-Load oder für jeden einzelnen Abschnitt setzt. Auch hier möchte ich nicht zu tief in die Diskussion einsteigen. Darüber würde ich gerne in einem separaten Text diskutieren. Wir setzen den Zeitpunkt, wenn ein Abschnitt in den Core geladen wird, damit wir die Information zu bestimmten Abfragezeitpunkten wiederherstellen können. Wenn der Staging-Zeitpunkt relevant ist, würde ich ihn als Attribut im Satellite behalten. Das bedeutet aber nicht, dass ich andere Sichtweisen hier für falsch halte – nur für anders.
Die 3d-Achse ist insofern besonders, als sie unter der Kontrolle des DWH-Teams liegt. Und viele, die schon lange in diesem Bereich arbeiten, wissen: Wir vertrauen keinem Quellsystem :)

3d-Achse: Eine Information ersetzt die andere implizit (ja, Petr ist die korrekte Schreibweise meines Namens)
Worüber reden wir eigentlich / Korrekturen vs. echte Historie
Wenn wir nun davon ausgehen, dass der Load ins DWH sehr nah an der Erfassung im Quell-System liegt, speichern wir die 2d-Zeit einfach als Attribut im Satellite und ignorieren sie in einem ersten Schritt. Also wenn wir von SCD Type 2 sprechen: ist es 1d oder 3d? Das ist nicht immer klar und hängt teilweise von der Branche ab. Im Versicherungsbereich ist es zum Beispiel für viele Objekte im Quellsystem Pflicht, eine 1d-Historie zu führen, und daher ist dies für die meisten Versicherungsanwender die primäre Zeitdimension. In anderen Branchen ist weniger bekannt (vielleicht außer bei einigen Objekten wie der Adresse), dass die Daten bereits eine 1d-Historie aus dem Quellsystem haben, und daher wird die 3d zur primären Zeitachse.
Es ist wichtig zu verstehen, dass die 3d-Achse in einer perfekten Welt eigentlich genau einen Zweck hätte: zu zeigen, was das DWH zu einem bestimmten Zeitpunkt wusste. Ein Beispiel könnte sein, dass am 2. Februar die Provisionsauszahlungen für Januar berechnet werden und der Report Wochen oder Monate später exakt gleich reproduziert werden kann, auch wenn sich die Daten im Quellsystem inzwischen geändert haben, weil z. B. bestimmte Verträge nicht wie erfasst abgeschlossen wurden. Vor allem dann, wenn man spätere Korrekturen nicht berücksichtigen möchte oder die unkonigierten Zahlen mit explizit ausgewiesenen Korrekturen darstellen muss.
Das Problem ist, dass bestimmte Daten, die im Quellsystem eine 1d-Historie haben sollten, diese nicht haben, weil das Quellsystem dies vereinfacht gesagt nicht unterstützt. Zum Beispiel kann es für bestimmte Auswertungen der Logistikabteilung relevant sein, dass ich bei meiner ersten Bestellung in einem Online-Shop in Zürich wohnhaft war, bei meiner zweiten aber in Basel. Daher wird die 3d-Achse als beste Näherung an die 1d-Achse verwendet, wenn die Adresse nicht bereits im Quellsystem historisiert ist.
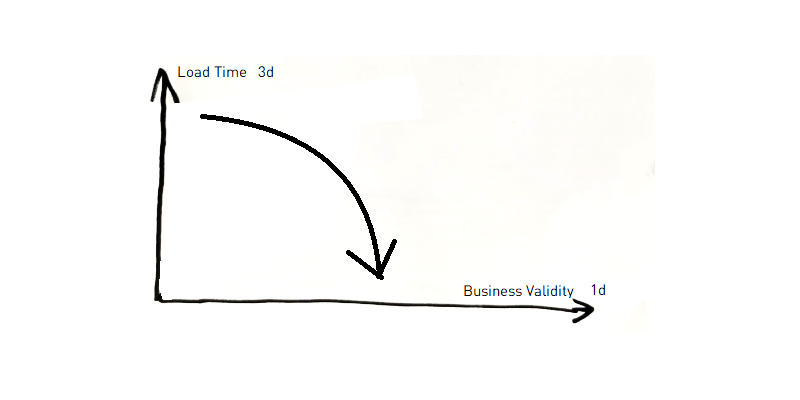
In manchen Unternehmen ist dies so üblich, dass kein Unterschied zwischen 1d und 3d gemacht wird.
Nun gibt es eine weitere Komplikation: Wenn im Modell kein Unterschied zwischen Historie und Korrektur gemacht wird, vermischen sich noch mehr Dinge. Wird z. B. mein Vorname im Quellsystem korrigiert, handelt es sich normalerweise um eine Korrektur. Auch wenn wir sie aus Nachvollziehbarkeitsgründen als neuen Eintrag im Satellite im Data Vault speichern, ist das keine fachliche Historie. Es kommt sehr selten vor, dass jemand einen neuen Vornamen erhält. Dennoch habe ich bei manchen Unternehmen erlebt, dass genau diese Änderung in Form einer SCD Type 2-Dimension direkt in Reports übertragen wurde. Das macht Reports nicht nur unnötig kompliziert, sondern kann sie sogar verfälschen. Da wir in bestimmten Ländern jedoch manchmal nicht zwischen Korrekturen und echter Historie – wie der Namensänderung bei einer Heirat – unterscheiden können, müssen wir möglicherweise das Muster wählen, das die Mehrheit der erwarteten Fälle abdeckt.
Echte Historie vs. relevante Historie
Aber selbst wenn eine echte Historie vorliegt: Wenn es für mein Geschäftsmodell irrelevant ist, wie eine Person einmal geheißen hat (es sei denn, ich verkaufe Namenszusätze): Warum nehme ich diese Information in einen Report auf? Das sind Fragen, die – wie Michael Müller es treffend formuliert – von den Business-Anwendern beantwortet werden müssen. Da wir aber damit rechnen müssen, dass zukünftige Business-Anwender ihre Meinung darüber ändern, was sie benötigen, speichern wir die vollständige Historie trotzdem auf der 3d-Zeitachse. Das bedeutet nicht, dass wir diese Information in Reports ausgeben.
Konkret: Für Mailing-Listen zur Information bestimmter Kundengruppen über neue Produkte oder für Rückruforganisationen ist möglicherweise nur der aktuelle Kundenname auf der 3d-Achse relevant. Ob der Name korrigiert wurde oder ob die Person früher einen anderen Namen hatte, ist irrelevant. Dasselbe gilt für bereits im Quellsystem erfasste 1d-Historie: Für einen Serienbrief ist es unerheblich, wo der Kunde in der Vergangenheit gewohnt hat oder in Zukunft wohnen wird. Nur der aktuell gültige Wohnort bezüglich 1d und 3d zählt.
Meine Annahme ist daher: Je nach Auswertungsziel müssen wir entweder echte 1d-Fachhistorie in die Reports einbringen oder – wo nicht vorhanden, aber relevant – die 3d-Achse als beste Näherung für 1d verwenden. *In vielen Fällen ist es jedoch sinnvoller, eine Point-in-Time-Sicht (je nach fachlichem Bedarf auf Attributebene as-now, as-then oder as-of zu einem bestimmten Zeitpunkt) in die Reports zu geben, weil sie die Reports einfacher nutzbar macht und die Gefahr einer Fehlauswertung verringert. 2
Das ist in der Tat ein Schnitt durch unsere zweidimensionale Zeitfläche zur einer Zeitachse.
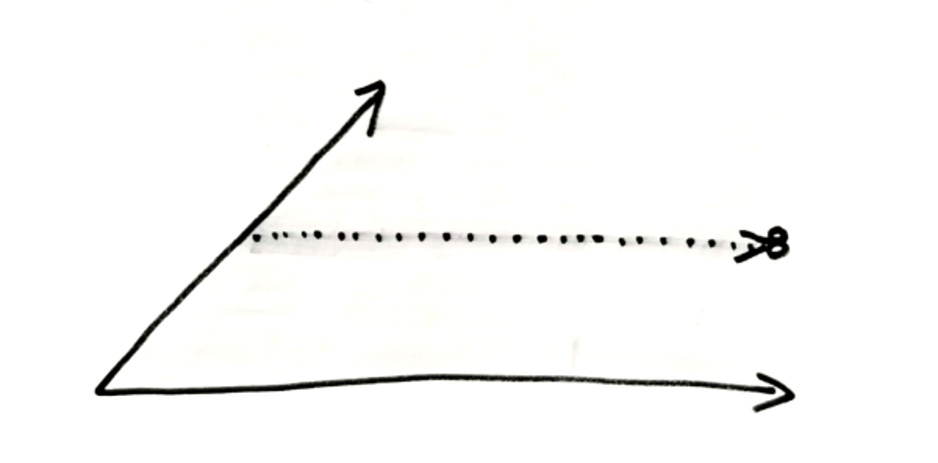
Und von der Zeitachse zum Zeitpunkt:

Eine beispielhafte Anforderung könnte lauten: Ich möchte die Kundenadresse as-now auf der 3d-Achse und as-now auf der 1d-Achse wissen. Ich erhalte den aktuellsten Namen gemäß unserem neuesten Kenntnisstand.
Oder: Ich möchte die Abteilung eines Vertriebsmitarbeiters as-of 31. Januar 2020 auf der 3d-Achse, aber zum Zeitpunkt des Vertragsabschlusses durch den Kunden (as-then) auf der 1d-Achse wissen.
Das zweite Beispiel besagt: Ich möchte nichts über Korrekturen wissen, von denen das Data Warehouse nach dem 31. Januar erfahren hat, und ich möchte die Abteilung kennen, in der ein Vertriebsmitarbeiter arbeitete, als er einen Deal abschloss. Ich möchte seinen Umsatz nicht umbuchen, wenn er später die Abteilung wechselt.
Wie man 1d-Historie im DWH modelliert *3
Es gibt einige grundlegende Unterschiede: Interpretiere ich die Zeit vor dem Laden in den Data Vault (vgl. auch die guten Arbeiten und Kurse von Dirk Lerner), oder lade ich zunächst alles aus dem Quellsystem in den Raw Vault, auch wenn wir überlappende Time Slices erhalten? Wir haben den zweiten Ansatz gewählt, weil Nachvollziehbarkeit im Vault für uns nur gegeben ist, wenn wir alle Daten erfassen können, so fehlerhaft sie auch sein mögen.
*** 2. „Vereinfachung" / Strategie: einen Temporal Instance Hub erstellen,*** *** indem der Business Key mit der fachlich gültigen From-Zeit konkateniert wird***
Das bedeutet, dass wir mehrere gültige Einträge für einen Business Key – z. B. eine Vertragsnummer – erhalten, auch wenn sie nicht aktuell sind. Wir erhalten also mehrere Tupel mit beschreibenden Attributen für denselben Business Key. Im Data Vault-Muster kann ein Satellite genau ein Tupel für einen Business Key während eines Loads speichern. Das ist insofern verwirrend, als er im Laufe der Zeit mehrere Tupel haben kann. Diese Tupel repräsentieren jedoch die 3d-Historie – nicht die 1d-Historie, bei der mehrere gültige Tupel gleichzeitig existieren.
Die Lösung besteht entweder darin, einen sogenannten Multi-Active Satellite (MA Satellite, auch Multi Valued Satellite genannt – manche Modellierer nennen ihn explizit Bi-Temporal Satellite) zu verwenden, oder die Granularität des Hubs zu ändern. Ich nenne das einen Temporal Instance Hub.
Beide Ansätze haben Vor- und Nachteile. Der MA Satellite macht das Modell schlanker, da kein spezieller Hub für eine bi-temporale Version des Objekts eingeführt werden muss. Der Nachteil: Ich kann im Modell keine spezifische Instanz des Objekts mehr referenzieren. *4
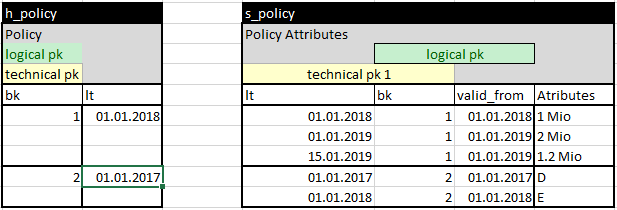
Beispiel: Im Versicherungsbereich habe ich eine Police mit einer definierten Deckung. Diese Deckung kann sich jedoch im Laufe der Zeit anpassen. Wichtig: Das ist normalerweise keine Korrektur, sondern es entsteht eine neue Instanz der Police. Zum Beispiel kann meine Deckung für 2018 1 Million betragen, die ich 2019 auf 2 Millionen erhöhe.
Nun wird ein Schadensfall gemeldet. Der Kunde meldet ihn im Februar 2019, es wird jedoch festgestellt, dass der Schaden bereits im November 2018 entstanden ist.
Wenn ich nun die Lösung mit dem MA Satellite gewählt habe, kann ich den Schaden nur einer bestimmten Police als Ganzes verknüpfen und muss die Auswahl der passenden Policeinstanz in einer Business Rule definieren, um feststellen zu können, ob die Deckung ausreicht.
Wenn ich dagegen die Lösung mit dem Policy Instance Hub gewählt habe, kann ich den Schaden direkt mit der passenden Instanz verknüpfen.
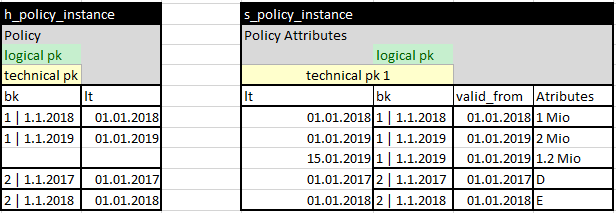
Wenn nun eine Korrektur erfolgt – weil im Januar 2019 festgestellt wird, dass die Deckung falsch erfasst wurde und für 2019 statt 2 Millionen 1,2 Millionen betragen sollte – bereitet das dem MA Satellite erneut Probleme: Ohne zusätzliche Regeln weiß ich nicht, welchen Eintrag im Satellite ich ersetzen soll. Das macht ein mögliches Delta-Load-Konzept, das dies bereits auflöst, zu einem Custom-Load-Pattern mit zusätzlichen Metadaten.
Diese Logik muss ich möglicherweise ebenfalls in den Business Rule-Teil verschieben, und sie ist im Modell nicht mehr direkt sichtbar.
Auch hier hat der Temporal Instance Hub einen klaren Vorteil: Wenn nur ein Time Slice geändert wird, wird er mit einem Standard-Load-Pattern korrekt auf der 3d-Zeitachse aktualisiert, ohne alle anderen Instanzen dieses Vertrags laden zu müssen. Da der logische PK nur aus der BK-Spalte besteht, die als Verkettung der ID plus der fachlich gültigen From-Zeit definiert ist.
Aus diesen Gründen unterstützen wir den Temporal Instance Hub-Ansatz in unserem Tool. Aber wie beschrieben ist es nicht die einzig mögliche Lösung. Nicht zu verwechseln mit dem Keyed-Instance-Konzept, das eine Lösung zur Erstellung eines Hubs beschreibt, der die identifizierenden Schlüssel einer Transaktion abbildet.
Wenn ich also einen Temporal Instance Hub habe, kann ich ihn auch inklusive der 1d-Historie mit einer 3d-as-now (auch As-Of-Now genannt)-Sicht sehr einfach ausgeben – indem ich einfach den letzten Eintrag pro Business Key in meinem Satellite auswähle, und die Struktur meiner Reports wird trivial. *7
Was ist mit relevanten dimensionalen Attributen: Instantiierung
Auch wenn ich oben beschrieben habe, dass bestimmte Attributänderungen für viele Auswertungen nicht relevant sind, gibt es durchaus solche Änderungen, die zentral sind.
Ein Beispiel ist einer unserer Kunden, der die Möglichkeit hat, bestimmte Produkte selbst herzustellen oder zu kaufen, bevor er sie an seine Kunden verkauft.
Für Qualitätssicherungszwecke ist es wesentlich, ob das Produkt vom Kunden selbst oder von einem externen Unternehmen verkauft und geliefert wurde. Natürlich wäre es ideal, wenn das Quellsystem diese Information bereits erfasst. Leider ist in diesem Fall die Einstellung im Produktstammsystem zum Zeitpunkt der Bestellung die einzige Quelle dieser Information. Diese Einstellung wird daher im Quellsystem weder historisiert noch instantiiert. Deshalb müssen wir die 3d-Historie als beste Näherung verwenden.
Wir haben also den Fall, dass eine 3d-Zeitachse als Näherung für die 1d-Sicht verwendet wird. Wenn wir nun beim klassischen Kimball-Modellierungsansatz bleiben, geben wir eine Auftragsposition als „Fakt" aus. In diesem Fall würden die Produkteigenschaften als SCD Type 2-„Dimension" ausgegeben. Da wir hier keine 1d-Zeitachse haben, würde die 3d-Zeitachse für die SCD Type 2-Historisierung verwendet, und ein Valid From und Valid To würden darauf basierend berechnet. Auch hier meine ich, dass die Verwendung der Bezeichnungen Valid From und To für die 3d-Achse zu Verwirrung führt – versuchen Sie daher, diese zu vermeiden.
Andere Produktattribute wie der Produktname sollten jedoch ohne Historie ausgegeben werden, da Änderungen an diesen Attributen normalerweise einer Korrektur entsprechen.
Das bedeutet, dass die Dimension einmal in einer SCD Type 2-Version und einmal in einer SCD Type 1 (as-of-now)-Version in den Report übertragen wird. Tatsächlich müssen wir nun zwei Foreign Keys einbeziehen: den Business Key selbst plus den Business Key kombiniert mit dem korrekten Time Slice – der in der Kimball-Welt oft durch einen Surrogate Key repräsentiert wird.
Das bedeutet zusätzliche Komplexität im Report und zusätzliche Komplexität bei der Erstellung des Facts. Auch wenn es jetzt aussieht, als könnten wir verschiedene Zeitsichten kombinieren, ist dies in der Regel nicht der Fall: Der Name wird in diesem Beispiel immer as-now (as-of-now) und die Produkteigenschaft immer as-then (as-of-then) gelesen. *5
Was ist also eine einfache Lösung, die dieselben Analysen im Report ermöglicht, aber die Modellierung des Data Marts/Report-Views vereinfacht? Im Data Vault-Modellierungsansatz gibt es einen sehr einfachen Weg: Wir können dieses Attribut vom Produkt-Hub auf den Auftragspositions-Hub übertragen. Dies geschieht durch einen Business Vault Load zum Zeitpunkt, wenn die Transaktion in den Raw Vault geladen wird, der ein as-of-now Lookup auf das Produktattribut durchführt und es dann in einem Business Vault Satellite auf der Transaktion speichert. Es ist trivial, weil wir keine historischen Abfragen auf der 3D-Achse durchführen müssen, und es ist effizient, weil wir es nur für neue Transaktionen tun müssen. Der einzige Einwand könnte sein, dass diese Materialisierung Speicherplatz verbraucht. Das ist aber bei Datenbanken, die columnar storage unterstützen, kein wirkliches Problem, da die wenigen Instanzen solcher Attribute ohnehin komprimiert werden. Ich nenne dieses Verfahren Instantiierung eines Attributs auf einer anderen Granularität. *8
*** 3. Vereinfachung / Strategie: Attribute zu einem bestimmten Zeitpunkt auf Transaktionen instantiieren***
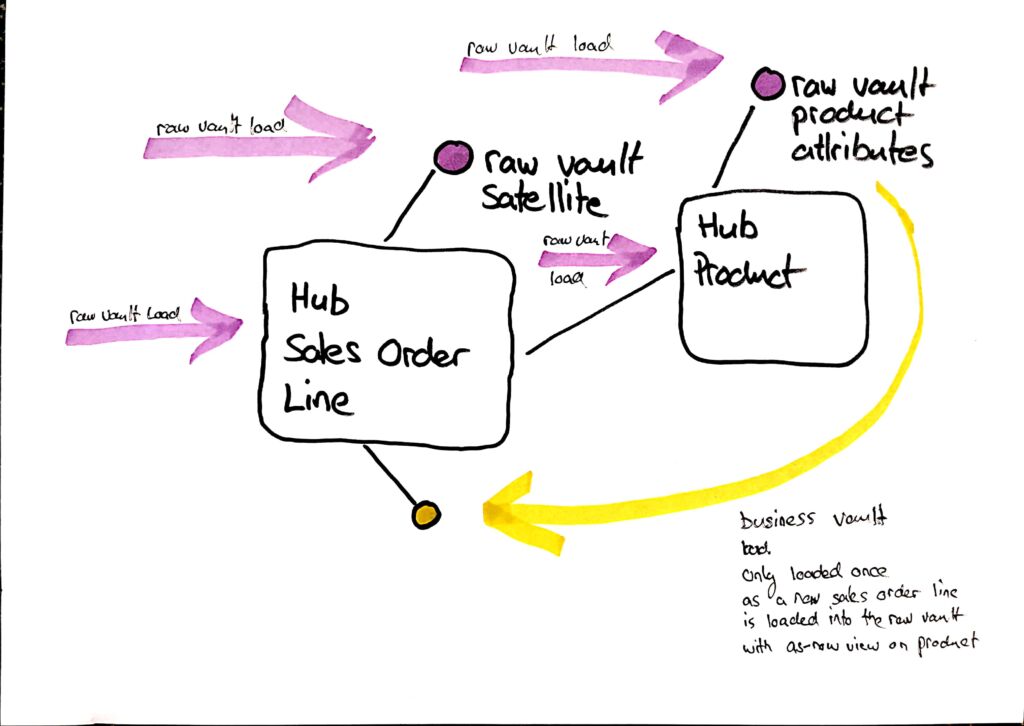
Wenn wir nun den Verkaufsauftrag ausgeben, können wir auch das Business Vault-Attribut auf dieser Transaktionsgranularität ausgeben. Jeder Anwender versteht, dass dieses Attribut etwas zum Zeitpunkt der Transaktion ist. Es sind keine Lookups beim Export in die Reports notwendig, und es gibt keine mehrfachen Dimensionen mehr für dasselbe Objekt.

Kurze Zusammenfassung
Mit diesen drei Vereinfachungen / Strategien:
-
2d nur als Attribut im Satellite speichern
-
die 1d-Zeit in den Hub-Schlüssel einbeziehen
-
Attribute auf der Transaktion instantiieren
behaupte ich, dass wir in den meisten Branchen die Mehrheit der Anforderungen an eine historisierte Ausgabe abdecken können.
In einem dritten Artikel werde ich die Fälle diskutieren, in denen das nicht ausreicht, und welche technischen Lösungen für solche Anforderungen existieren.
Fußnoten
1 Das Beispiel mit Basel als Wohnort ist vollständig erfunden – natürlich würde ich nie in Betracht ziehen, in Basel zu leben, so wie kein „Basler" erwägen würde, in Zürich zu leben, soweit das zu verhindern ist.
2 Wiederum ausgenommen sind spezielle Reports: Wenn ich z. B. die Qualität der Dateneingabe im Quellsystem auswerten möchte, können solche Namensänderungen natürlich relevant sein.
3 Kann analog auch für 3d-Historie verwendet werden, wenn diese als Näherung für 1d genutzt wird.
4 Das Problem, dass mehrere MA Satellites ohne spezielle Regeln nicht verknüpft werden können, weil sonst ein Kreuzprodukt entsteht, behandle ich nicht im Detail, weil man mit dem speziellen Subtyp des bi-temporalen Satellites ein automatisiertes Muster finden kann, um die Einträge korrekt auszukreuzen, wenn man die Zeit-/Datumsfelder in den Metadaten erfasst.
5: Sie können das Ganze auch anders abbilden, indem Sie nur die as-then (as-of-then)-Dimension im Fact verknüpfen und dann einen Self-Link auf der Dimension selbst für die as-now (as-of-now)-Werte herstellen. Dies wird von bestimmten Reporting-Tools wie QlikView etc. nicht unterstützt. Der Hauptgrund, warum ich diese Variante nicht aufgeführt habe, ist aber, dass sie den Report meiner Meinung nach nicht einfacher, sondern komplizierter macht.
7 Diesen Ausdruck habe ich von einigen ETH-Professoren in Zürich übernommen, die mathematische Formeln auf der zwei Räume breiten Tafel aufschreiben und am Ende erklären, dass es – weil es deterministisch ist – trivial ist.
8 Hier lasse ich mich gerne belehren, falls es einen passenderen / klareren Ausdruck gibt.