Multi-Active Satellites im Data Vault
Petr Beles über die Implementierung von Multi-Active Satellites als Document Satellites im Data Vault: Muster, Abwägungen und praktische Empfehlungen.
Petr Beles, 2150 GmbH, https://staging.datavault-builder.com 2018-11-07
Multi-Active Satellites als Document Satellites implementieren
Im Data-Vault-Standard gibt es ein Muster namens Multi-Active Satellite. Es wird auch teilweise verwendet, um Bi-Temporalität im Data Vault abzubilden.
Einem Business Key in einem Hub mit einer bestimmten Granularität wird mehr als ein gültiger Eintrag im Satellite für einen Zeitpunkt zugewiesen (gemäß der DWH-Kenntniszeit oder Assertion Time).
Ich versuche zu erklären, warum Multi-Active Satellites in bestimmten Fällen eingesetzt werden, wann man besser darauf verzichten sollte und wie man sie implementieren könnte, wenn man sich dennoch dafür entschieden hat.
Gründe für die Verwendung von Multi-Active Satellites
- Es gibt wirklich keinen Schlüssel, um die verschiedenen Zeilen für denselben Business Key zu unterscheiden
In der Realität ist das meiner Erfahrung nach selten der Fall, und die Daten werden häufig falsch interpretiert: Selbst bei einem Kunden mit verschiedenen unklassifizierten Telefonnummern kann jede Nummer eindeutig identifiziert werden – über die Nummer selbst.
Außerdem gilt: Wenn kein Identifikator vorhanden ist, können technische Duplikate in der Quellschnittstelle nicht erkannt werden. Daher sollte das Quellsystem nach Möglichkeit aufgefordert werden, die Datenlieferung anzupassen.
- Aus Performance-Gründen
Wenn ein eindeutiger Unterschlüssel vorhanden ist, kann man alternativ einen weiteren Hub auf der feineren Granularität definieren und diesen sauber über einen Link verbinden – als Alternative zum Multi-Active Satellite. Damit lassen sich Standard-Lademuster für alle Satellites und Abfragen verwenden, allerdings müssen zwei zusätzliche Objekte geladen und abgefragt werden (wobei der zusätzliche Hub in einigen Datenbanken durch Table-Elimination-Optimierung die Abfragen nicht beeinflussen sollte).Original Multi-Active Satellite Design
Gründe, auf Multi-Active Satellites zu verzichten
Eine erste Herausforderung ist, dass ein Multi-Active Satellite nur dann mit Delta-Loads befüllt werden kann, wenn alle Zeilen für einen Hub-Key im Delta-Extrakt vorhanden sind. Als Alternative sind stets Full Loads möglich.
Eine weitere Herausforderung zeigt sich beim gemeinsamen Abfragen des Multi-Active Satellite mit dem Hub, weil die unterschiedliche Granularität zu einer Vervielfachung der Hub-Datensätze führt (auch bekannt als Fan-out) – selbst bei einer Abfrage für eine bestimmte Assertion Time. Das erhöht die Komplexität in den nachgelagerten Schichten erheblich.
Und nicht zuletzt: Was passiert, wenn man einen PIT für zwei oder mehr Multi-Active Satellites auf demselben Hub erstellen möchte? Ich gehe davon aus, dass man im Kreuzprodukt-Chaos endet – für immer.
Das wichtigste Argument ist jedoch meiner Meinung nach: Wenn man auf die feinere Granularität verlinken möchte, sollte man daraus einen eigenen Hub erstellen. Beispielsweise bei Versicherungsverträgen: Die Instanz eines Versicherungsvertrages ist definitiv ein eigenständiges Objekt, auf das Schadensfälle verknüpft werden können. Hier würde ich persönlich immer einen Contract Hub und einen Contract Instance Hub modellieren, anstatt einen Multi-Active Satellite zu verwenden.
Lösungsvorschlag für die Implementierung: Document Satellite
Angenommen, man hat einen validen Anwendungsfall für einen Multi-Active Satellite – wie würde ein gutes Lademuster aussehen?
Beim Treffen der Deutschen Data Vault User Group (DDVUG) in Hamburg im Oktober 2018 diskutierten Torsten Glunde, Andreas Heitmann, Matthias Müller, jemand dessen Namen ich leider vergessen habe, und ich eine Lösung, die einige der Implementierungsprobleme lösen würde:
Unter der Voraussetzung, dass alle aktiven Zeilen für einen Business Key ohnehin gleichzeitig im Staging vorhanden sein müssen (entweder durch einen Full Load oder durch ein entsprechend gestaltetes Delta), kann man aus diesen Zeilen eine Menge bilden.
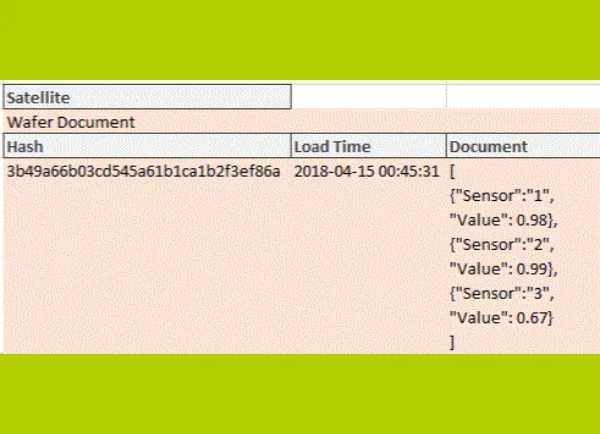
Es gibt Datenbanken, die native Arrays als Feldtypen unterstützen, die zur Speicherung von Mengen genutzt werden können. Praktischer heutzutage ist möglicherweise ein JSON-Dokument, das bereits auf den meisten Plattformen unterstützt wird. Neben Hierarchien kann ein JSON-Dokument auch Mengen darstellen.Proposed document satellite design.
Wenn man also alle Zeilen in einem JSON-Dokument in einem einzigen Satellite-Datensatz speichert, stimmt die Granularität von Hub und Satellite zu einem gegebenen Assertion-Zeitpunkt wieder überein. Damit lassen sich dieselben Standard-Lademuster für alle Satellites verwenden.
Für die Downstream-Verarbeitung entsteht weder bei der PIT-Erstellung noch in anderen Leseschichten ein erhöhter Komplexitätsaufwand. Nur wenn die geschäftliche Anforderung besteht, die Menge in einzelne Zeilen aufzulösen (also das JSON-Dokument zu parsen), kann man das bewusst an dem Ort tun, wo es gewünscht ist. Das kann in der Präsentationsschicht oder im Report geschehen, wo Fan-out erwünscht ist.
JSON-Dokumente in Datenbanken
Mit wachsender Verbreitung von JSON-Dokumenten gibt es auch zunehmend Unterstützung für deren Verarbeitung in verschiedenen Datenbanken – wie beispielsweise der binäre Vergleich in PostgreSQL. Mit diesem Feature werden irrelevante Unterschiede im Dokument ignoriert, und ein neuer Satellite-Datensatz wird nur eingefügt, wenn sich der Inhalt tatsächlich geändert hat. In allen Fällen muss man die Tupel beim Erstellen eines Arrays sortieren, da JSON-Arrays geordnet sind.
Wenn die Datenbank hingegen nur einen textbasierten JSON-Vergleich unterstützt, müssen aktive Maßnahmen ergriffen werden, um irrelevante Unterschiede durch eine Art Formatierungsnormalisierung (prettify) zu ignorieren.
Epilog
Die Verwendung von JSON in Satellites ist natürlich nicht neu und kann auch in anderen Fällen eingesetzt werden: Dan Linstedt selbst hat die Verwendung von JSON-Dokumenten für die Verarbeitung dynamischer Quelldaten beschrieben: https://danlinstedt.com/allposts/datavaultcat/datavault-2-0-supports-dynamic-data-warehousing/