Integration und Vereinheitlichung von Daten
Integration oder Unioning in Data Vault? Dieser Artikel erklärt den entscheidenden Unterschied und zeigt, wie Sie große Datenmengen optimal verarbeiten.
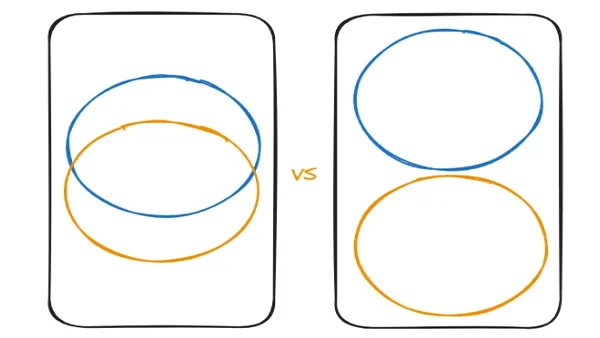
Unioning versus Integration von Hubs – Warum der Unterschied entscheidend ist
In Data Vault Modeling nutzen wir Hubs zur Integration von Daten. Das ist allgemein bekannt und einer der Hauptgründe, warum wir Data Vault Modeling wählen: um Daten aus verschiedenen Datenquellen zu integrieren. Aber was bedeutet „Integration" eigentlich? Ich habe bisher keine Diskussion darüber gesehen, wie wir Daten tatsächlich integrieren.
In diesem Artikel vereinfache ich meine Beispiele – ich weiß, dass die Realität komplexer sein kann als hier dargestellt. Für das Verständnis des Grundkonzepts ist es jedoch hilfreich, es einfach zu halten.
In Gesprächen mit Carsten Schweiger haben wir zwei unterschiedliche Muster identifiziert: Integration und Unioning.
Integration vs. Unioning
Diese Unterscheidung ist wichtig, da sie bestimmt, wie wir Daten optimal verarbeiten können. Charakterisieren wir die beiden Optionen:
Integration
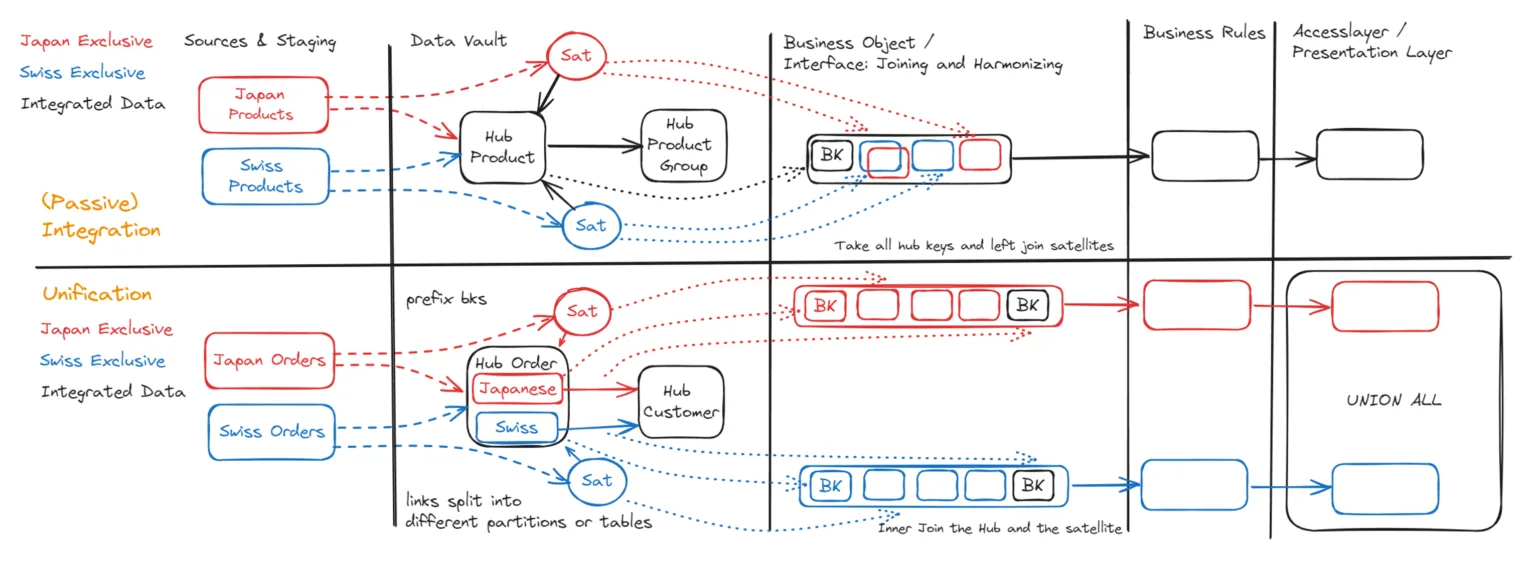
Auch als passive Integration bezeichnet: Wir haben zwei verschiedene Quellsysteme mit demselben Business Key. Ein häufiges Beispiel ist das Produkt mit der Produktnummer, die mehr oder weniger erfolgreich zwischen verschiedenen Systemen geteilt wird.
Wenn wir den Listenpreis in der Schweiz und in Japan vergleichen möchten, können wir die Schweizer ERP-Daten und die japanischen ERP-Daten in den Product Hub laden. Die Produktnummer wird ohne Präfix in den Hub geladen, und die Attribute werden in einen japanischen und einen Schweizer Satellite geladen.
Wenn wir nun eine Ausgabeschnittstelle über dem Data Vault erstellen (in Datavault Builder nennen wir das ein „Business Object"), selektieren wir alle Keys aus dem Hub. Wir können dann den Schweizer Listenpreis in eine Spalte und den japanischen Listenpreis in eine andere Spalte schreiben.
Falls der Schweizer Listenpreis der Masterwert ist, es aber einige Japan-exklusive Produkte gibt, könnten wir eine dritte Spalte mit Priorisierungsregeln erstellen: Wenn der Schweizer Preis gefüllt ist, wird dieser genommen; wenn der Schweizer Listenpreis leer ist, wird der japanische Preis verwendet. Das ist der Use Case, den wir – zumindest ich – meistens im Kopf haben, wenn wir ein Data Vault-Projekt starten.

Warum müssen wir also Unioning unterscheiden? Der Unterschied liegt darin, dass die Datensätze aus zwei verschiedenen Quellsystemen nicht überlappend / exklusiv sind. Ein gängiges Beispiel ist der Order Hub. Die Bestellungen aus der Schweiz und aus Japan werden in diesem Hub vereint, aber Bestellnummer 101 kann sowohl in der Schweiz als auch in Japan existieren, ohne dass es sich um dieselbe Bestellung handelt.
Das bedeutet:
-
Wir müssen unsere Bestellnummern mit einem Präfix versehen, um die Datensätze getrennt zu halten, und
-
Wir müssen keine Rechenleistung aufwenden, um die Bestellungen aus den beiden Quellsystemen mit ausgeklügelten Mitteln zu kombinieren.
-
Wir können die Daten bis zur Präsentationsschicht getrennt halten, was die Datenmenge reduziert, die gejoint werden muss.
-
Wir können die Verarbeitung dieser beiden Datenströme beim Laden in den Data Vault vollständig parallelisieren.
-
Wir können die Datenselektion aus dem Data Vault ebenfalls vollständig parallelisieren.
Das Gute ist, dass die großen Datensätze in der Regel Unioning- und keine Integrations-Datensätze sind.
Wenn wir Unioning Hubs als eigenes Muster akzeptieren:
-
Müssen wir die Business Keys beim Hub-Load mit einem Präfix versehen, da es überlappende Nummernbereiche geben kann, die nicht dasselbe bedeuten.
-
Können wir Link-Tabellen erstellen, die nach System partitioniert sind (oder separate Link-Tabellen). Das ermöglicht das parallele Laden.
-
Dies ermöglicht auch eine effizientere Leseoperation, da die Anzahl der zu joinenden Zeilen für jedes Quellsystem reduziert wird – und diese Reduktion ist exponentiell in Bezug auf die Anzahl der Quellsysteme.
-
Der Output kann separat vorbereitet werden. Die Harmonisierung von Spaltennamen kann virtuell auf Systemebene erfolgen.
-
Business Rules können auf Systemebene verarbeitet werden.
-
Für den vereinheitlichten Output kann am Ende ein generiertes UNION ALL-Statement verwendet werden, um die Datensätze aus den verschiedenen Quellen zusammenzuführen.
-
Das ermöglicht es der Datenbank, die Selektion der verschiedenen Quelldatensätze zu parallelisieren und Filter auf bestimmte Datensätze sowie auf spezifische Satellite-Spalten nach unten zu pushten.
Dies ermöglicht eine schnellere Erstellung des vollständigen Datensatzes, erlaubt aber auch die Filterung auf einzelne Systeme sowie das Push-down von Filtern auf spezifische Satellite-Spalten.
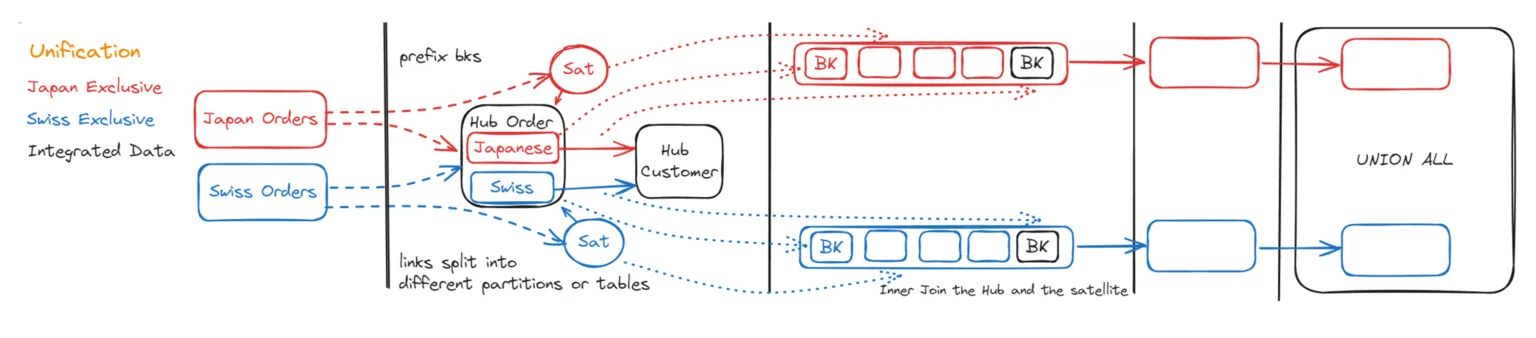
Durch die Unterscheidung zwischen Integration und Unioning können wir die Muster für Entitäten mit großen Datenmengen optimieren. Darüber hinaus verdeutlicht diese Unterscheidung im Datenmodell den Zweck der Datenintegrations-Pipeline und hilft zu bestimmen, welche Objekte sinnvoll für eine aussagekräftige Ausgabe gejoint werden können.
Wie Integration und Unioning automatisiert werden
Im folgenden Video sehen Sie, wie diese beiden Use Cases vollautomatisch in Datavault Builder konfiguriert werden: