Sind Equi-Joins immer besser?
Sind INNER JOINs wirklich immer besser als LEFT JOINs? Ein reproduzierbarer Test auf Snowflake zeigt: die Antwort ist differenzierter.
Es kommt immer wieder vor, dass ich auf Aussagen stoße, wie Datenbanken funktionieren und wie sie abgefragt werden sollen. Und ich lese diese Empfehlungen gerne. Besonders dann, wenn sie mit einer theoretischen Erklärung einhergehen. Noch lieber lese ich solche Kommentare, wenn sie mit Tests untermauert werden, die die Theorie beweisen. Der beste Fall ist immer, wenn die Skripte veröffentlicht werden und reproduziert werden können.
Häufig werden solche Performance-Aussagen jedoch ohne jeglichen Beweis pauschal getroffen: Muster X ist immer besser als Y. Das mag zutreffen, wenn man mehr Wissen über den Dateninhalt hat als die Datenbank – oder wenn es eine mathematische Erklärung für dieses Verhalten gibt.
Meiner Meinung nach sollten Aussagen über Indizierungsstrategien oder Join-Strategien in den meisten Fällen auf bestimmte Datenbanktechnologien und -versionen beschränkt werden. Aussagen ohne reproduzierbare Tests sollten nicht als selbstverständlich hingenommen, sondern geprüft werden.
Wenn ich etwas auf SQL Server 2008 teste und mit SQL Server 2019 vergleiche, erhalte ich in der Regel völlig unterschiedliche Ergebnisse, da sich SQL Server stark weiterentwickelt hat. Vergleiche ich Postgres mit Snowflake und Exasol, erhalte ich ebenfalls unterschiedliche Ergebnisse, da Letztere von Grund auf für analytische Abfragen konzipiert wurden.
Das ist der Grund, warum ich folgende Aussage in Frage stellen möchte:
„Equi-Joins (INNER JOINs) sind immer besser als LEFT JOINs"
Warum das relevant ist
Wenn man dieser Empfehlung folgt, ohne sie zu testen, kann das zu schlechter Performance führen. Da wir mit unserem Datavault Builder-Tool im Automatisierungsbereich tätig sind, wirkt sich die Wahl des falschen Musters hundert- oder gar tausendfach aus.
Warum LEFT JOINs besser sein können
Zunächst: Unter bestimmten Bedingungen sind INNER JOINs tatsächlich besser. Als Beispiel: Sie ermöglichen es dem Query-Optimizer, Abfragen von beiden Enden einer Join-Kette aus zu starten. Wenn dadurch das Zwischenergebnis erheblich reduziert werden kann und für die verbleibenden, größeren und indizierten Tabellen nur wenige Zeilen nachgeschlagen werden müssen, ist das ein klarer Vorteil. Es gibt viele weitere Szenarien, auf die ich hier nicht im Detail eingehen werde.
Aber das gilt nicht immer:
Stellen Sie sich 2 Szenarien vor:
-
Sie haben 10 Tabellen. Eine hat 15 Millionen Datensätze, die anderen 9 je 45 Millionen. Alle Verbindungen gehen von der 15-Mio.-Tabelle direkt zu den umliegenden Tabellen. Alle 15 Mio. Datensätze haben einen übereinstimmenden Eintrag in den anderen 9 Tabellen. — Führen Sie INNER JOINs aus.
-
Führen Sie LEFT JOINs aus.
-
Sie haben 10 Tabellen. Eine hat 30 Millionen Datensätze, die anderen 9 je 45 Millionen. Alle Verbindungen gehen von der 30-Mio.-Tabelle direkt zu den umliegenden Tabellen. 15 Mio. Datensätze haben einen übereinstimmenden Eintrag in den anderen 9 Tabellen – 15 Mio. Datensätze nicht. — Führen Sie INNER JOINs aus (und fügen Sie Dummy-Datensätze in die 9 Tabellen ein, da Sie sonst die 15 Mio. nicht übereinstimmenden Datensätze verlieren würden).
-
Führen Sie LEFT JOINs aus.
Das ist das Szenario, das ich am 26. August 2021 auf Snowflake ausgeführt habe (das Datum ist relevant, da Snowflake ständig verbessert wird).
Meine Annahme war: LEFT JOINs performen bei dieser Art von Abfrage besser. Warum? Ich habe dieselben Tests vor zwei Jahren für SQL Server (2017) und Oracle (12c) durchgeführt und kam auf Basis meiner Messungen für dieses Szenario zu dem Schluss, dass LEFT JOINs besser abschneiden.
Die Theorie dahinter: Zumindest im zweiten Fall kann die 30-Mio.-Tabelle vor dem Join gefiltert werden, was schneller sein sollte. Im Fall, wo alles übereinstimmt, würde ich dieselbe oder eine minimal schlechtere Performance erwarten, da der FILTER auf der 15-Mio.-Tabelle etwas bremsen könnte (vielleicht einige Prozent).
Wir werden sehen, dass meine Erwartungen mit meinen Messungen übereinstimmen – ich bin mir jedoch nicht zu 100 % sicher, ob meine Erklärung korrekt ist, da ich keinen Low-Level-Zugriff auf die internen Abläufe der Datenbank habe. Es könnte alternative Erklärungen geben – etwa, dass das Übertragen der Dummy-Datensätze (15 Mio. ×) die INNER JOIN-Variante verlangsamt. Ich weiß es schlicht nicht mit Sicherheit. Aber ich sehe, dass sie in den meisten Messungen langsamer ist. Falls Sie auf Datenbankebene wissen, was passiert, freue ich mich über Ihren Kommentar.
Außerdem kann ich bei Verwendung eines LEFT JOIN weniger Daten speichern, da ich einen NULL-Wert verwenden kann, um anzuzeigen, dass es keinen übereinstimmenden Datensatz in den anderen Tabellen gibt – anstatt diesen in einer Spalte oder Zieltabelle beim 2-Spalten-Ansatz zu speichern. Im 1-Spalten-Surrogatschlüssel-Ansatz kann dieser NULL-Wert im Schlüssel kodiert werden, was keinen großen Overhead erzeugt. Im ersten Fall belegt die Tabelle jedoch das 5-Fache des Speicherplatzes! Im zweiten Fall verwendet die für INNER JOINs vorbereitete Tabelle immer noch 50 % mehr Speicher.
Alle Werte wurden mit 30 Mio. geladenen Datensätzen gemessen.
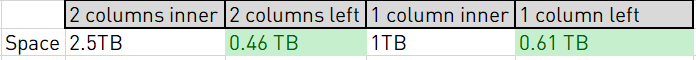
Testing
Ich habe den Ergebnis-Cache deaktiviert, aber den Daten-Cache nicht nach jeder Abfrage vollständig geleert. Das führte zu einigen interessanten Ergebnissen: Bei der 2-Spalten-INNER-30m-Tabelle war der Test mit 3 Tabellen langsamer als der mit 6 Tabellen im nächsten Schritt. Da dies reproduzierbar war, nehme ich an, dass es mit dem Daten-Cache zusammenhängt.
Alle Tests wurden mindestens 3 Mal ausgeführt. Ergebnisse wurden akzeptiert, wenn die Abweichung zwischen den Läufen weniger als 10 % betrug.
Obwohl die Anzahl der durchzuführenden JOINs und die Anzahl der zurückgegebenen Zeilen überall gleich ist, sind die Abfrageergebnisse nicht zu 100 % identisch: Mit INNER JOINs erhalte ich für die 9 übereinstimmenden Tabellen Einträge, die ich als Dummy-Werte wie „N/A" nutzen könnte. Im Ausgabetest habe ich versucht, diese Dummies mit COALESCE zu setzen – das machte jedoch keinen Unterschied, sodass ich diesen Teil aus meiner Abfrage entfernt habe. Um den Test zu verbessern, könnte es sinnvoll sein, Standardwerte auch mit einer CASE-Bedingung zu setzen (falls Sie zwischen „Match gefunden, aber Spalte NULL" und „kein Match" unterscheiden möchten).
Ergebnisse
Ich habe zwei Arten von Tests durchgeführt: Joins zwischen der 15-Mio./30-Mio.-Tabelle und den 9 anderen über 2 Spalten oder nur über 1 Spalte (unter Verwendung eines Surrogatschlüssels, der die ersten beiden Felder kombiniert).
In allen Fällen mit meinem Datenvolumen auf Snowflake heute hat die LEFT JOIN-Variante etwa gleich gut oder besser abgeschnitten. Wie immer gab es in einzelnen Läufen einige Ausreißer. Hier ist die Ausgabe einiger Läufe inklusive der Ausreißer (wie die 147 Sekunden im zweiten Lauf für 2-Spalten-LEFT JOIN):




Der 2-Spalten-/9-Sats-Load im zweiten Lauf war ein nicht reproduzierbarer Ausreißer.
Fairerweise sei erwähnt: Der INNER JOIN auf einer Spalte scannt etwa 20–25 % weniger Daten (da kein Filter benötigt wird). Da es sich aber um einen lokalen Scan handelt, schadet das nicht und beschleunigt den JOIN-Teil – was insgesamt in Ordnung ist.
Man sieht außerdem, dass das Joinen über 1 Spalte erwartungsgemäß deutlich effizienter ist als über 2 Spalten.
Zu beachten ist, dass beim S-Sized-Lauf meine Erwartung ist, dass der LEFT JOIN-Ansatz im 1-Spalten-Szenario, bei dem alles übereinstimmt, etwa 5 % weniger effizient ist (da der Filter angewendet wird, aber nichts entfernt). Im 2-Spalten-Szenario ist er jedoch deutlich besser, da er weniger I/O erzeugt.
Ich habe auch die Anzahl der Ausgabespalten variiert (Selektion aus 3 statt nur aus einer Zieltabelle) und geprüft, ob das einen Einfluss hat: Nein, hat es nicht.

Auf die Darstellung der Ausführungspläne habe ich verzichtet, da sie sehr ähnlich aussehen.
Zusammenfassung
In bestimmten Fällen haben INNER JOINs eine bessere Performance als LEFT JOINs. Aber nicht immer. Ich habe mit reproduzierbaren Tests gezeigt, dass LEFT JOINs unter bestimmten Bedingungen nicht schlechter oder sogar deutlich besser abschneiden als INNER JOINs.
Ich möchte keine universelle Aussage über mein Szenario treffen. Ich sage nur: Auf bestimmten Datenbanken, in bestimmten Versionen, für bestimmte Abfragen können LEFT JOINs die bessere Option sein.
Außerdem haben wir gesehen, dass auf Snowflake das Joinen über 1 Spalte deutlich besser ist als über 2 Spalten.
Selbst testen
Es ist möglich, dass mir etwas entgangen ist. Habe ich Key-Definitionen falsch gesetzt? Den Cache falsch geleert oder das SQL nicht optimal geschrieben? Reproduzieren Sie die Ergebnisse gerne selbst.
Das Testskript kann hier heruntergeladen werden: