Data Vault vs. Data Mesh — ein Widerspruch?
Schließen sich Data Vault und Data Mesh aus? Petr Beles erklärt, warum die Kombination aus Data Mesh, Data Vault und Automatisierung die richtige Antwort ist.

Sollte ich noch Data Vault einsetzen, wenn es Data Mesh gibt? In den vergangenen Wochen und Monaten wurde mir diese interessante Frage mehrfach gestellt. Ich versuche hier, mein Verständnis und meine Gedanken dazu darzulegen. Wenn Sie eine abweichende Meinung haben, kontaktieren Sie mich gerne auf LinkedIn für eine Diskussion. Falls ich irgendeinen Aspekt des Data-Mesh-Konzepts falsch verstanden habe, lassen Sie es mich bitte wissen.
Es könnte hilfreich sein, meinen Hintergrund und was meine Meinung geprägt hat zu kennen, um mein Argument zu verstehen. Ich arbeite seit dem Jahr 2000 mit Daten. Ich habe verschiedene technologische Entwicklungen miterlebt — von Sybase-Clients, die zu Oracle migriert haben, bis hin zu Oracle-Clients, die zu Cloud-Datenbanken wie Snowflake wechseln. Ich habe erlebt, wie Inmon-3NF-Modellierungsansätze manchmal durch Dimensional Modeling ersetzt oder ergänzt wurden, und den Aufstieg der Data-Vault-Modellierung beobachtet.
Ich sehe Data-Vault-Modellierung stets als eine Weiterentwicklung der Inmon-3NF-Modellierung, die in vielen Fällen in Kombination mit einem Dimensional-Output für Reporting-Zwecke eingesetzt wird.
In den vergangenen 22 Jahren haben wir immer wieder erlebt, dass Business-User schnellere Berichte, einfacheres Datenverständnis und vieles mehr forderten. Der Druck führte manchmal zu einer anderen Technologie oder einem anderen Modellierungsansatz.
In anderen Fällen entfachte er eine Diskussion darüber, wie viel zentralisiert (spezialisiertes Team) und wie viel dezentralisiert werden sollte. Diese Spannung ist nicht neu.
Mein Verständnis — und das ist meine persönliche Meinung: Data Mesh ist eine Antwort auf die Herausforderung, dass das zentrale Datenteam in bestimmten Unternehmen mit einem zentralisierten Ansatz zum Engpass werden kann. Diese Situation kenne ich sehr gut. Ich war selbst Teil dieses Problems.
Daher teile ich viele der Standpunkte, die Zhamak Dehghani in ihren Werken zum Ausdruck bringt. Dennoch denke ich, dass dieser Ansatz am besten für große Unternehmen geeignet ist, die die Ressourcen haben, Data-Spezialisten in verschiedene Domänen einzubetten.
Mein Argument ist, dass mittelgroße und auch größere Unternehmen stärker von zentralisierten Teams profitieren könnten, indem sie modellgetriebene Automatisierung einsetzen, um den Engpass in den zentralisierten Teams als alternativen Lösungsansatz zu beseitigen. Ich muss darauf hinweisen, dass ich hier befangen sein könnte, da ich für das Datavault-Builder-Team arbeite — DWH-Automatisierung ist unser Thema.
Für größere Konzerne, in denen Automatisierung allein nicht ausreicht, weil sie Skalierbarkeit nicht vollständig löst, könnte die Dezentralisierung mit einem formalisierten Ansatz, wie er in „Data Mesh" beschrieben wird, das Richtige sein. In den folgenden Abschnitten diskutiere ich Data Vault vs. Data Mesh in genau diesem Kontext.
Data Vault vs. Data Mesh?
Wer lieber ein Video schaut als liest: Die Aufzeichnung von der Knowledge Gap Conference ist hier verfügbar.
Stark vereinfacht und in meiner Interpretation dessen, was ich gelesen habe: Data Mesh erklärt, dass Enterprise-Datenmodelle tot sind. Die Datenmodellierung und Implementierung der „Datenflüsse" soll in Domänen aufgeteilt und unabhängigen Teams — den Domänen — zugewiesen werden.
Bedeutet das, dass Data Vault aus der Gleichung verschwindet? Das glaube ich nicht.
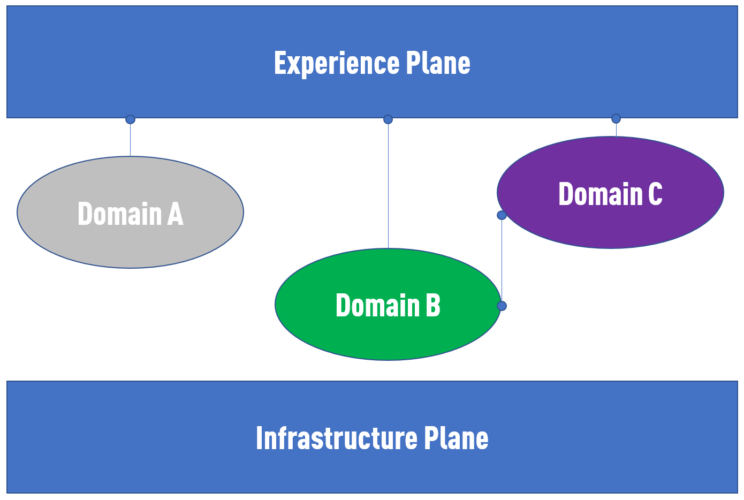 Wir sehen verschiedene Data-Product-Provider zwischen der Infrastruktur und der Mesh „Experience Plane." Data Mesh schreibt den Domänenteams nicht vor, wie sie diese erstellen sollen. In vielen Fällen würde ich dafür plädieren, dass dies der ideale Ort für einen automatisierten Data-Vault-Ansatz ist.
Wir sehen verschiedene Data-Product-Provider zwischen der Infrastruktur und der Mesh „Experience Plane." Data Mesh schreibt den Domänenteams nicht vor, wie sie diese erstellen sollen. In vielen Fällen würde ich dafür plädieren, dass dies der ideale Ort für einen automatisierten Data-Vault-Ansatz ist.
Warum? Wenn man in der Vergangenheit mit ETL-Ansätzen feststeckte, kann die Aufteilung in kleinere Domänen das Skalierungsproblem des zentralisierten Datenteams lösen und einige Komplexitäten reduzieren. Es beseitigt jedoch nicht viele andere Probleme — fehlende Dokumentation oder viel manuelle Arbeit zum Beispiel.
Wer jemals einen ETL-Flow rückwärts entwickeln musste, um die implementierte Geschäftslogik zu verstehen, weiß, was ich meine.
Modellgetriebene Ansätze beginnen auf der anderen Seite — mit dem Verständnis, worum es bei den Daten geht. Wir hatten in der Vergangenheit auch schlechte Erfahrungen mit Enterprise-Datenmodellen, weil ihre Erstellung Monate dauerte, man einen Doktortitel brauchte, um sie zu verstehen, und das Datenteam sie ignorierte, weil sie zu abstrakt waren. Aus dieser Erfahrung heraus weiß ich, dass viele Leute Datenmodelle vollständig abschaffen wollen.
Dennoch brauchen wir sie, denn sie liefern einen enormen Mehrwert und lösen viele Probleme — aber wir brauchen den richtigen Umgang damit.
Data Vault hat die Probleme des 3NF-Enterprise-Datenmodells gelöst, indem es eine lose Kopplung zwischen Entitäten verwendet. Das ermöglicht es, klein mit dem Datenmodell zu beginnen, es sofort zu implementieren und später zu erweitern. Dieser Ansatz schafft früh Mehrwert und macht Sie agil.
Der Nachteil: Data Vault erzeugt durch Hypernormalisierung viele technische Objekte. Das bedeutet, dass Sie für die manuelle Implementierung eines Data Vault in Ihren Domänenteams viele Data Engineers benötigen würden — und alle Implementierungen wären unterschiedlich. Das bedeutet auch, dass Sie für Sidecar-Implementierungen in jeder Domäne das Rad neu erfinden müssen.
Und hier kann ich zu meinem Lieblingsthema zurückkehren: Automatisierung. Automatisierung hilft Ihnen innerhalb der Domänen, den Aufwand und das Wissen zu reduzieren, das für die Implementierung Ihrer Data Products notwendig ist, indem ein Datenmodell automatisch in funktionierenden Code umgewandelt wird.
Sie löst auch viele der von Zhamak Dehghani definierten Anforderungen — klares Data Lineage, korrekte Historisierung der Daten und vieles mehr.
Im Datavault Builder erhalten Sie beispielsweise auch automatisierte Infrastruktur, Schnittstellen zum Einbinden Ihrer Sidecars und visuelle Tools zur Definition Ihrer Data Products — als denormalisierte Sicht auf den hochnormalisierten Data-Vault-Kern.
Darüber hinaus wird das Modell über den Standard-Softwareansatz mit GIT-Flow versioniert, was alle Probleme bei der Modell- und Data-Product-Bereitstellung löst.
Über Docker-Deployment und die bereitgestellten APIs können Sie Ihren CI/CD-Workflow auf unkomplizierte Weise einrichten.
Da ein automatisierter Data-Vault-Ansatz modellgetrieben ist, ermöglicht er es Ihnen auch, alle im Buch beschriebenen Modell- und Laufzeit-Metadaten automatisch zu generieren und abzufragen — ohne manuelle Entwicklung.
Ich denke, das ist eine perfekte Symbiose. Bedeutet das, dass jede Datendomäne eine automatisierte Data-Vault-Implementierung verwenden sollte? Wahrscheinlich nicht.
Wie Zhamak Dehghani beschreibt, sollte die Implementierung innerhalb der Domäne nicht vorgeschrieben werden — manche Teams, die hauptsächlich mit nicht-historisierten Maschinendaten arbeiten, könnten sich aus gutem Grund für eine nicht-modellierte Kafka-Alternative entscheiden. Aber Teams, die Daten aus verschiedenen Quellen zusammenführen und integrieren müssen, sind damit auf jeden Fall gut bedient.
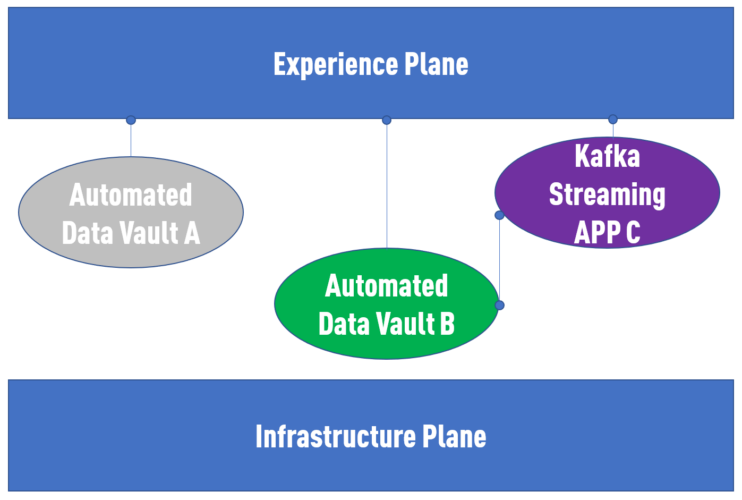 Fazit: Data Mesh + Data Vault ist die Antwort. Präziser formuliert: Data Mesh + Data Vault + Automatisierung.
Fazit: Data Mesh + Data Vault ist die Antwort. Präziser formuliert: Data Mesh + Data Vault + Automatisierung.
Zentrales vs. dezentrales Datenmodell
Das „Data Mesh"-Buch bleibt bei konkreten Implementierungsdetails vage. Und bitte verstehen Sie das nicht als Kritik — ich denke, das ist so beabsichtigt, da es eine Vision eröffnet, die auf viele verschiedene Weisen implementiert werden kann. Aus meiner Perspektive denke ich jedoch immer über die konkrete Implementierung einer spezifischen Architektur nach und wie sie bis ins letzte Detail funktionieren wird. Dieser Abschnitt befasst sich also damit, wie man es implementiert und operationalisiert.
Wir verstehen, dass die Modellierungsverantwortung auf Teams aufgeteilt werden kann — in Data-Mesh-Begriffen zwischen Domänen. Das haben wir seit Jahren praktiziert, zum Beispiel in multinationalen Unternehmen mit einem zentralen Plattformteam und lokalen Datenteams, die die Länderbesonderheiten kennen.
Das zentrale Team definiert zentrale Entitäten wie den „Kunden" oder das „Produkt." Jetzt werden hoffentlich die ersten Leute anfangen zu klagen, dass wir wieder Engpässe schaffen, die wir durch zentral designte Entitäten beseitigen wollten!
Hören Sie mich an: Ich befürworte keine zentrale Implementierung dieser Objekte. Nur eine konzeptionelle Definition, dass diese Objekte existieren. Diese abstrakte Definition entspräche dem Zeichnen einer Entität auf Ihre Leinwand in einer ER-Welt. In Data Vault wäre das ein Hub. In beiden Fällen erhält diese Entität/dieser Hub eine eindeutige ID, die in allen Domänen erkannt werden kann. Im Datavault Builder verwenden wir Smart Keys, um diese Konzepte zu identifizieren — technische IDs könnten aber ebenfalls für Sie funktionieren.
Sobald Sie festgestellt haben, dass diese Konzepte existieren, können Sie diese „Prototypen" in die verschiedenen Domänen verteilen. Jede Domäne würde ihre eigene Instanz des Datavault Builder betreiben. Die Domänenteams entscheiden innerhalb ihrer Instanz, wie sie diese Konzepte mit Daten befüllen (d. h., welche Teilmenge von Kunden in ihre Implementierung des „Kunden" eingeht), welche Attribute sie über diese Kunden speichern und welche Geschäftsregeln auf sie angewendet werden sollen.
Dieser Prozess der zentralen Definition des Vorhandenseins von Dingen und der Verteilung der Definitionen an die Datendomänen kann im Datavault Builder vollständig automatisiert werden. Das ist möglich, weil unsere Datenmodelle — sowohl das zentrale als auch das lokale — so erstellt sind, dass sie über einen GIT-Prozess gebrancht und gemergt werden können. Das bedeutet, dass dieser Prozess keine Domänenteams blockiert oder zusätzliche Arbeit für sie erzeugt.
Im Gegenteil: Wenn ein Domänenteam glaubt, dass ein Konzept aus seiner Domäne auch in anderen Domänen verwendet werden sollte (etwa indem es mit anderen Konzepten verknüpft wird), kann es es dem zentralen Modell hinzufügen — und es wird automatisch an die anderen Teams verteilt.
Ein offener Punkt, den Sie für Ihr Unternehmen definieren müssen: ob das zentrale Modell nur das Konzept als solches verwaltet ODER ob Sie auch eine Definition des identifizierenden Schlüssels für eine Entität hinzufügen.
Sie könnten beispielsweise nur ein Konzept einer „Währung" erstellen ODER definieren, dass Sie ein „Currency ISO2"-Konzept haben, das durch den ISO-2-Buchstabencode identifiziert wird, und ein „Currency ISO3"-Objekt für den 3-Buchstaben-Code. Das hängt davon ab, wo Sie sich auf Ihrer Zentralisierungs-Dezentralisierungs-Reise befinden.
Der Vorteil dieses Ansatzes: Wenn das Revenue-Assurance-Team eine Relation zur zentral erstellten Entität eines „Kunden" erstellt, definiert das vollautomatisch auf der Experience Plane, wie Daten zwischen dem Kunden und den Revenue-Assurance-Domänen verknüpft werden können. Wenn Sie die Schlüssel auch zentral definiert haben, wissen Sie, dass es sogar semantisch funktioniert.
Dieser Hinweis wird im Data Product durch die Verwendung eindeutiger Namen für die Schlüsselspalten zentral erstellter Entitäten gegeben — wie „Business Key of Customer."
Kurz zusammengefasst: Im zentralen Modell wird eine Entität namens „Kunde" erstellt. Eine Domäne könnte Details über den Kunden implementieren, wie Name und Adresse. Die andere implementiert im Rechnungsdaten-Produkt eine Relation zu Kunden. Beide Produkte sind vollständig unabhängig. Aber durch einen „Business Key of Customer" in beiden resultierenden Data Products weiß die Experience Plane, wie diese 2 Data Products zusammenhängen, und kann eine Abfrage auf dem „gejointen" Datensatz durchführen.
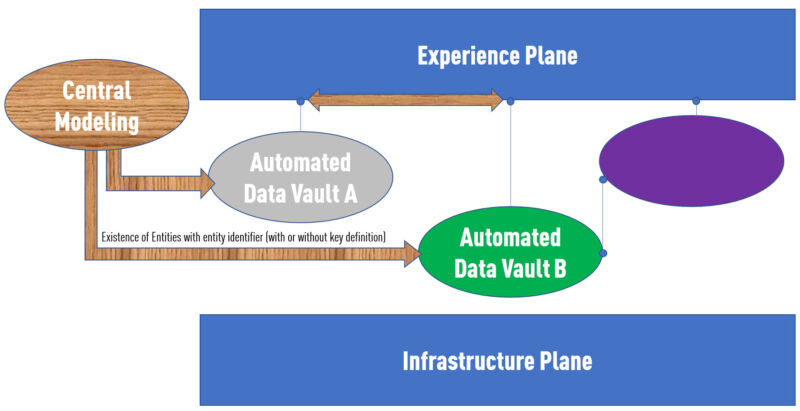 Wie man zwischen Datendomänen joined
Wie man zwischen Datendomänen joined
Nachdem Sie nun wissen, wie Sie verschiedene Data Products logisch joinen können, bleibt die Frage, wie Sie das technisch umsetzen. Im Data-Mesh-Buch wird vorgeschlagen, URI-Relationen zwischen Objekten zu verwenden. Dieser Ansatz könnte für kleinere Abfragen funktionieren — oder bei Technologien, mit denen ich für größere Datenmengen nicht vertraut bin. Meine Erfahrung zeigt jedoch, dass dieser Ansatz performance-technisch schwierig werden kann.
Da der Datavault Builder für die meisten Schichten ein ELT-Tool ist, speichern wir alle Ergebnisse auf Datenbankebene mit virtuellen Schnittstellen (Views). Das bedeutet: Selbst wenn verschiedene Datendomänen, die den Datavault Builder einsetzen, vollständig isolierte Instanzen auf separaten Datenbanken betreiben, aber dieselbe Datenbanktechnologie wie Snowflake, Azure Synapse, MSSQL Server oder Oracle verwenden, können sie Joins über Cross-Database-Abfragen durchführen. Diese Cross-Database-Abfragen werden über die Data-Mesh-Experience-Plane gesteuert — außerhalb der einzelnen Datavault-Builder-Instanzen.
Wenn die verschiedenen Datavault-Builder-Instanzen keine gemeinsame Datenbanktechnologie verwenden oder wenn nicht-relationale Daten eingebunden werden sollen, können Virtualisierungsprodukte wie Denodo eingesetzt werden.
Mein Punkt ist: Es gibt eine klare Schnittstelle jeder einzelnen Datavault-Builder-Instanz innerhalb einer Domäne, die die Data Products als Datenbankschnittstellen (die auch als APIs bereitgestellt werden können) ausgibt und alle Metadaten sowie die vereinbarten Schlüsselspalten-Namen automatisch an die Experience Plane liefert — damit diese Schicht ihr „Magic" entfalten kann. Danach kann die Experience Plane entscheiden, verschiedene Domänen über Datenbank- oder Virtualisierungstechnologie zu joinen und die Daten als Datenbankschnittstelle (JDBC/ODBC) oder API an die Konsumenten zu liefern.
Datavault Builder
In diesem Abschnitt möchte ich erläutern, warum wir glauben, dass der Datavault Builder das richtige Tool zur Implementierung von Data Vault in einer Data-Mesh-Lösung ist.
-
Cloud-Native — betreibbar auf einer standardisierten Infrastrukturebene
-
Automatisiertes Infrastruktur-Setup — über Docker-Deployment können neue Umgebungen per Konfiguration gestartet werden
-
CI/CD — alle Deployment-Aktionen können über APIs ausgelöst werden
-
Modellgetriebene Automatisierung — weniger technische Kenntnisse in den Datendomänen notwendig
-
Git-Flow-basiert — Datenmodelle können gebrancht und gemergt werden, was verteilte Entwicklung innerhalb der Domänenteams ermöglicht
-
Zentrale & verteilte Modelle — die eingebaute Fähigkeit, Kernelemente zentral zu erstellen und auf lokale domänengetriebene Instanzen zu verteilen
-
Visuelles Data-Product-Komposition — der normalisierte Kerndatenspeicher kann als Data Product präsentiert werden
-
Automatisiertes Data Lineage
-
Automatisierte Dokumentation
-
Alle Metriken in Echtzeit verfügbar
-
Der Data-Vault-Ansatz ermöglicht es, klein zu beginnen und das Domänenmodell über die Zeit zu erweitern
Kostenlose persönliche Präsentation
[
Hier klicken ](https://wp.gr5qncwxtlc5sqo.static3.studiorequest-a-demo/)







