Data Vault & Databricks Medallion-Architektur
Data Vault und Lakehouse gelten oft als unvereinbar. Dieses Webinar zeigt, warum Data Vault 2.0 und Databricks Medallion Architecture eine Stärke sind.

Jahrelang hat ein verbreiteter Einwand Teams davon abgehalten, Data Vault mit Lakehouse-Plattformen zu kombinieren: zu viele Tabellen, zu viele Joins, zu viel Komplexität für Big Data. In diesem Webinar begegnen Simon Dudanski und Thomas Voigt von b.telligent sowie Petr Beles von Datavault Builder diesem Missverständnis direkt — und zeigen, warum die Kombination aus Data Vault 2.0 und der Databricks Medallion Architecture kein Widerspruch, sondern eine Stärkenverbindung ist.
Die Medallion Architecture in drei Schichten
Databricks organisiert den Datenfluss über drei klar definierte Verantwortungsbereiche:
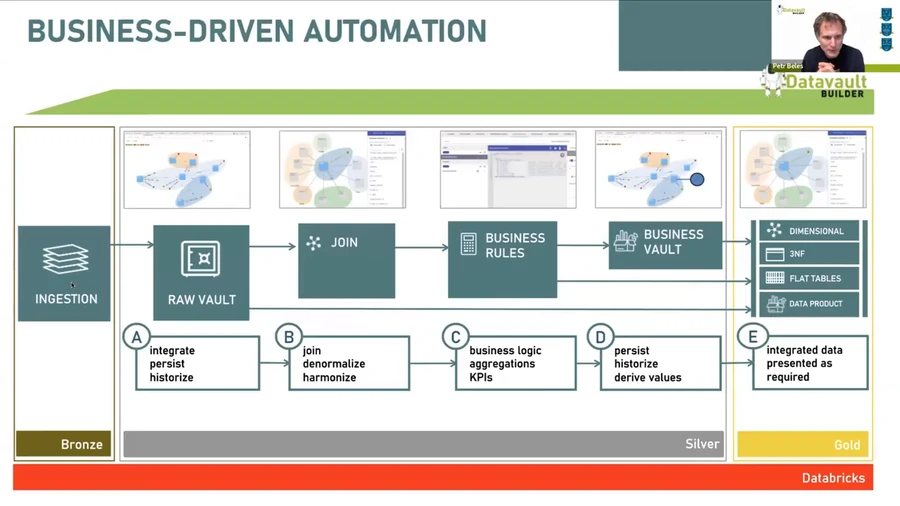
- Bronze — Rohe, unveränderte, historisierte Daten aus Quellsystemen. Die Landing Zone. Schnelle Ingestion, volle Auditierbarkeit.
- Silver — Bereinigte, validierte, integrierte Daten. Das zentrale Geschäftsmodell. Stabil gegenüber Änderungen im Quellsystem. Vollständige Historie wird beibehalten.
- Gold — Für den Konsum aufbereitete Daten, optimiert für BI, KI/ML und Data Products. Business-User arbeiten hier.
Die zentrale Erkenntnis aus dem Webinar: Silver ist der natürliche Platz für Data Vault. Der Raw Vault entspricht direkt der Silver-Schicht. Der Business Vault sitzt knapp darüber. Und die Gold-Schicht — Dimensional Models, Star Schemas, flache Tabellen — kann vom Datavault Builder automatisch aus demselben zugrundeliegenden Modell generiert werden.
Warum Data Vault in den Medallion Stack gehört
Drei Säulen machen Data Vault zum richtigen Modellierungsansatz für ein modernes Lakehouse:
1. Einheitliches Datenverständnis Data Vault stellt das Geschäftsmodell ins Zentrum der Plattform — nicht als einmaliges Artefakt, sondern als lebendige Struktur. Jeder Hub, Link und Satellite wird automatisch dokumentiert, und Data Lineage läuft von der Quelltabelle bis zur Berichtsspalte ohne manuelle Aufwände.
2. Modulare Geschäftsregeln Geschäftsanforderungen ändern sich. Data Vault ist genau dafür konzipiert. Jede Geschäftsregel ist isoliert — sie können Regeln hinzufügen, ändern oder stilllegen, ohne das restliche Modell zu beeinträchtigen. Flache Tabellen und 3NF-Modelle brechen unter Veränderungen zusammen. Data Vault nicht.
3. Skalierbarkeit über verschiedene Ladeverfahren Databricks bietet leistungsstarke Tools für Batch- und Streaming-Ingestion (Autoloader, Spark Streaming, Delta Live Tables). Die bi-temporalen Patterns von Data Vault — die sowohl erfassen, wann Daten ankamen, als auch wann sie im Quellsystem gültig waren — bewältigen beide Lademodi im selben Modell. Hubs und Satellites verarbeiten Streaming-Lieferungen außer der Reihe und Deduplizierung auf natürliche Weise.
Vollständige funktionale Parität auf Databricks
Datavault Builder auf Databricks liefert heute dieselbe funktionale Abdeckung wie auf Snowflake, BigQuery, SQL Server und allen anderen unterstützten Plattformen. Die Live-Demo im Webinar führt durch den vollständigen Workflow:
- Konzeptionelles Modellieren — Geschäftsobjekte visuell definieren; Databricks-Tabellen werden in Echtzeit erstellt
- Staging / Ingestion — Verbindung zu beliebigen Quellen; ETL/ELT-Code wird automatisch generiert und ausgeführt
- Raw Vault laden — Hubs, Links, Satellites mit vollständiger Historisierung und Delta-Handling
- Output-Bereitstellung — Dimensional Models und flache Tabellen werden aus demselben Modell für BI-Tools (Power BI, Tableau, Qlik) generiert
- Lineage und Deployment — automatische Dokumentation, Git-Versionierung, Deployment- und Rollback-Skripte; REST API für CI/CD-Pipelines
Ein typisches Enterprise-Projekt setzt 7–9 separate Tools ein, um diesen Prozess abzudecken. Mit Databricks und Datavault Builder sind es zwei.
Der praxisnahe Realitätscheck
Das Webinar schließt mit einer ehrlichen Einschätzung, wo diese Kombination am besten funktioniert:
- Batch-first oder Streaming-first-Projekte: Beide Patterns funktionieren. Für 99 % der Anwendungsfälle ist Micro-Batch im 1-Minuten-Intervall ausreichend — echtes Echtzeit-Processing ist nicht notwendig.
- Bestehende Databricks-Umgebungen: Datavault Builder verbindet sich direkt mit bestehenden Unity-Catalog-Datenbanken. Keine Migration erforderlich.
- KI- und ML-Pipelines: Gold-Layer-Data-Products sind bereits für Feature Stores und ML-Modelle strukturiert. Dieselbe Grundlage bedient BI- und KI-Workloads gleichermaßen.
Die Botschaft von Simon Dudanski, der ein Jahrzehnt damit verbracht hat, vom Aufbau von Data Vault auf Big-Data-Plattformen abzuraten, ist heute eindeutig: „Meine Welt ist vollständig. Ich habe alles, was ich brauche."
Möchten Sie sehen, wie Datavault Builder in Ihre Databricks-Umgebung passt? Buchen Sie eine kostenlose 20-minütige Demo — wir führen Sie durch Ihren konkreten Anwendungsfall.