Data Vault bi-temporal: Inscription Time
Wann ist Inscription Time im Data Vault relevant? Drei Lösungsansätze — von Persistent Staging bis bi-temporalen Satelliten — mit Praxisbeispielen aus dem Banking.
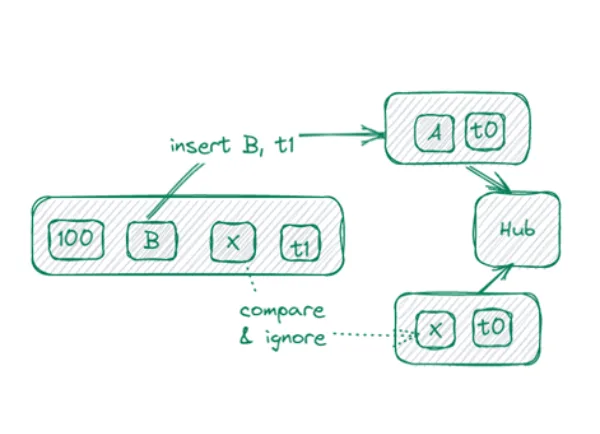
Als Beispiel: Wie man das Buchungsdatum-Problem in Banken löst
Eine Herausforderung, auf die wir häufig bei Banking- und Versicherungskunden stoßen, sind Daten, an die bereits eine oder mehrere Zeitlinien geknüpft sind.
Ich unterscheide dabei gerne drei Hauptzeitlinien. Im Versicherungsbereich können es sechs oder mehr sein, aber fangen wir mit den „Grundlagen" an.
Da wir primär mit IT-Systemen als Datenquelle arbeiten: Eine Zeitlinie, die immer existiert, ist die Inscription Timeline — für mich der Zeitpunkt, zu dem eine Information im Quellsystem erfasst wurde.
Für manche Daten ist damit alles gesagt. Sie werden nie in ein DWH übertragen und erheben keinerlei Ansprüche auf Vergangenheit oder Zukunft. Perfekt — fertig.
In unserem Fall werden diese Daten jedoch in Ihr DWH geladen. Nehmen wir an, Sie verwenden Data Vault als Designparadigma — aber das gilt gleichermaßen für alle anderen zeitbewussten Modellierungsansätze (nein, Data Mesh ist kein Modellierungs-, sondern ein Organisationsparadigma). Beim Laden in Hubs, Links und Satellites wird ein sogenanntes „Load Date" hinzugefügt (was glücklicherweise hoffentlich ein Timestamp ist). Ich verwende in diesem Kontext bewusst nicht „valid from" oder „valid to", da diese Begriffe dazu verleiten, diese Zeitlinie mit der geschäftlichen Gültigkeit zu verwechseln.
Wenn Sie diese Daten in wöchentlichem, täglichem oder stündlichem Rhythmus laden und dabei immer nur die aktuellste Information aus dem Quellsystem übernehmen, bleibt die Sache einfach — Sie fügen lediglich eine weitere Zeitlinie hinzu. Ihre Data Vault Automation hält alles im Griff, liefert die Information auf Wunsch als „as-of-now" und „as-of-then", und Sie sind zufrieden.
Ehrlich gesagt: Viele unserer Kunden haben keine höhere Komplexität als diese — und die sollten jetzt aufhören zu lesen und sich freuen. Dennoch empfehle ich: Lesen Sie meine Blogserie über Temporalität im Data Vault, denn selbst die as-of-then-Zeitlinie kann für manche bereits zu viel sein.
Wenn Sie in Ihrem Quellsystem eine geschäftliche Gültigkeit erfassen, lohnt es sich ebenfalls, meine früheren Blogbeiträge zu lesen, um zu verstehen, wie diese Information durch Erweiterung des Hub-Keys gespeichert werden kann.
Wenn die Inscription Timeline für Sie hingegen sehr relevant ist, ignorieren Sie bitte den Rat aus meinen früheren Beiträgen, dass Inscription Time vernachlässigt werden kann, solange die Load Time nah genug daran liegt.
Beispiele, in denen Inscription Time relevant ist:
· Sie erhalten Änderungen in sehr hoher Frequenz, Ihre DWH-Loads erfolgen seltener, und alle diese Änderungen sind für Sie relevant — sei es wegen ihres Geschäftswerts oder aus Auditierungsgründen. In diesem Fall ist Ihre Datenquelle höchstwahrscheinlich ein Change Data Capture (CDC)-Stream.
· Ihre Quelle ist nicht das Quellsystem selbst, sondern eine Art Export — und dieser Export enthält gelegentlich Fehler, unvollständige Daten oder beides, und die Daten werden zumindest unter bestimmten Umständen nachgeliefert.
· Die Inscription Time ist für Ihr Reporting eine genauere Zeitlinie als die Load Time — wie bei buchungsdatumsbasierten Daten (auch als Tages-End-Verarbeitung (TEV), COB, EOB bezeichnet), die die „wahre" Historie abbilden.
Kurz gefasst: Wenn Inscription Time für Sie relevant ist — Sie werden es in der Regel wissen.
Lösungsansatz: Inscription Time irrelevant machen
Wenn Sie den Zeitabstand zwischen der Erfassung im Quellsystem und dem Load in den Data Vault reduzieren, können Sie die Inscription Time in fast allen Fällen ignorieren und sich auf die Load Time verlassen — vorausgesetzt, Ihre Daten treffen in der richtigen Reihenfolge ein. Bei einem Kafka-Stream beispielsweise ist das nicht garantiert. Wenn Daten ungeordnet ankommen, würde dieser Ansatz vollständig falsche Ergebnisse liefern.
Lösungsansatz 1: Persistent Staging Layer erstellen
Mit dem Standard-Data-Vault-Pattern können Sie Ihren Change Key — das könnte der technische Schlüssel plus Inscription Time oder ein vom CDC-Stream gelieferter Change Key sein — zunächst alle Änderungen in Ihrem Persistent Staging Area (PSA) speichern. Darüber erstellen Sie dann eine Latest-View und laden diese in den Raw Vault. So bleiben Sie vollständig auditierbar, da alle Informationen im PSA erhalten bleiben.
Die Einschränkung: Das Raw-Vault-Bild wird nur bei Ihren Load-Intervallen aktualisiert, sofern Sie kein individuelles Load-Pattern erstellen. Das bedeutet: Änderungen im Sekunden- oder Mikrosekundenbereich werden im PSA gespeichert, aber nicht im Raw Vault, wenn kein Loop alle Datensätze in den Vault lädt. Für die meisten Anwendungen mit einem CDC-Stream kann das ausreichend sein — gleichbedeutend damit, den CDC-Stream zusammen mit dem Vault zu archivieren.
Das eigentliche Problem: Selbst wenn man Loops zum Laden des Vaults erstellt — kommen korrigierte oder ungeordnete Werte für die Vergangenheit an, können diese im Raw-Vault-Satelliten nicht an der richtigen Stelle einsortiert werden. Wenn es auch nur eine geringe Chance für dieses Szenario gibt und es erfasst werden muss, ist das ein K.O.-Kriterium. Lange Zeit war ich überzeugt, dass das zumindest bei sauberen CDC-Streams wie Attunity/Qlik Replicate oder Golden Gate kein Problem ist — bis Kafka kam.
Lösungsansatz 2: Inscription Time als Load Time
Ich bin immer für Komplexitätsreduktion — warum also nicht einfach die Inscription Time direkt in die Load-Time-Spalten laden? Klingt gut. Einfach zu implementieren. Die Data-Vault-Tabellenstrukturen müssen nicht geändert werden, und alle darüber liegenden Tools funktionieren weiter.
Theoretisch könnte das eine gute Lösung sein, wenn man davon ausgeht, dass die empfangenen Daten immer korrekt und nie nachkorrigiert werden. Das ist eine sehr schlechte Annahme:
Bei Exporten, die Ihnen geliefert werden, wird es immer Korrekturen geben.
Auch bei CDC-Streams: Werden sie unterbrochen, muss möglicherweise der Status der Basistabelle mit den bereits geladenen Daten abgeglichen werden.
· Buchungsdatuminformationen werden ebenfalls manchmal außer der Reihe geliefert.
Sobald Sie unterschiedliche Informationen für dieselbe Inscription Time erhalten, müssten Sie die bereits geladenen Daten löschen, in eine Archivtabelle verschieben oder sonstigen Flickenteppich betreiben.
Kurz: Selbst wenn es in einem sehr eingeschränkten Szenario eine Lösung sein könnte, ist die Wahrscheinlichkeit hoch, dass Sie früher oder später auf Fälle stoßen, in denen die gespeicherten Informationen bestenfalls unvollständig, schlimmstenfalls falsch sind.
Dennoch: Wer alle diese Probleme kennt und versteht, könnte damit sein Problem lösen. Da wir im Datavault Builder allgemeingültige Lösungen bereitstellen müssen, haben wir diese Option nach wenigen Wochen Beta-Testing entfernt — sie scheiterte in allen Praxistests. Und wenn ich „allen" sage, meine ich auch die, bei denen wir sicher waren, dass sie funktionieren würden. Meistens innerhalb weniger Tage. Manchmal innerhalb von Stunden.
Lösungsansatz 3: Bi-temporale Satelliten
Der richtige Ansatz ist die Verwendung eines Multi-Active Satellite, indem der Schlüssel im Satelliten um Hash-Key (HK), Load Time und Inscription Time erweitert wird.
Beim Laden werden nun HK und Inscription Time der gestagten Daten mit den Daten im Vault verglichen. Unterscheiden sich die Attribute oder fehlt der Eintrag, wird er mit dem aktuellen Timestamp als Load Time eingefügt.
Der Vorteil: Das Insert-Only-Pattern zum Laden des Satelliten kann weiterhin verwendet werden.
Nachteil: Es entsteht nun eine bi-temporale Historie darin. Treffen Daten ungeordnet ein, ist das in Ordnung. Die aktuelle Kenntnis über die Geschichte wird erst zur Lesezeit zusammengesetzt.
Das ist beim Abfragen dieser Daten jedoch eine Herausforderung. Diese lässt sich mit analytischen Funktionen lösen, indem entweder nach „Hash & Inscription Time" oder nur nach dem „Hash" partitioniert wird.
Der Nachteil: Die Performance kann schlecht werden, wenn verschiedene Abfragen gejoint werden, die jeweils eine analytische Funktion verwenden, um den korrekten Eintrag abzurufen. Aber wie Markus Winand sagt: „Use the index, Luke!" — genau das macht ein PIT-Table.
Selbst mit einem PIT besteht der Nachteil, dass der Link nun durch Hash, Inscription Time und Load Time definiert ist.
Glücklicherweise hat Patrick Cuba einen interessanten Artikel darüber geschrieben, wie Sequenzen genutzt werden können, um kompaktere PIT-Tables zu erstellen und Joins zu den Objekten durch eine Sequenzspalte in den Satelliten zu beschleunigen.
Fügt sich die Lösung in das DV2.0-Framework ein? Ich behaupte: ja. Der bi-temporale Satellit ist eine besondere Form des Multi-Active Satellite. Im Vergleich zu einem regulären Multi-Active Satellite kennen wir den „Sub-Partition-Key" jedoch von Anfang an — das ermöglicht auch das Delta-Loading.
Die Verwendung einer Sequenz im Satelliten für das Indexing ist für mich eine technologieabhängige Implementierungsentscheidung und ändert nichts an der Logik des Ansatzes (es werden lediglich drei Spalten durch eine kurze Spalte für schnellere Joins ersetzt).
Löst es alle Herausforderungen, die das Laden von Inscription Time notwendig machen können? So weit wir das beurteilen können: ja. Aber wieder hat uns die Realität gelehrt, dass es noch mehr gibt.
Kompression
Man könnte annehmen, dass ein CDC-Stream nur relevante Änderungen liefert. In der Realität ist das nicht immer der Fall. Doch selbst wenn: Sobald die Daten auf verschiedene Satelliten aufgeteilt werden, entstehen CDC-Zeilen, die in keinem bestimmten Satelliten eine Änderung verursachen. Daher muss Kompression angewendet werden. Auf den ersten Blick sieht es so aus, als könnte dasselbe Pattern wie bei normalen Satelliten angewendet werden.
Ungeordneter Eingang kombiniert mit Kompression
Sobald jedoch Daten für eine ältere Inscription Time erneut geliefert werden, kann das zu schwerwiegenden Problemen führen, wenn Datenzeilen für bestimmte Satelliten ignoriert wurden, weil sie keine neue Information enthielten. Wird später eine Information für eine ältere Inscription Time geliefert, kann das zu falschen Daten führen. Deshalb müssen alle komprimierten Informationen in einem Tracking-Satelliten nachgehalten werden.
Wenn eine Information ungeordnet eintrifft, kann aus dem Satelliten und dem Tracking-Satelliten die vollständige Historie rekonstruiert und die richtige Information eingefügt werden.
Hier ein Beispiel: Zu t0, t1 und t2 wurde der Wert „a" geliefert und komprimiert. Nun wird zu einem späteren Load-Zeitpunkt für die Inscription Time t1 der Wert „c" geliefert. Dieser Wert wird bei Inscription Time t1 in den Satelliten eingefügt — UND ebenfalls bei Inscription Time t2 muss der zuvor komprimierte Wert „a" nun eingefügt werden, da er sich vom Wert „c" bei t1 unterscheidet.
Für unsere deutschsprachigen Zuschauer haben wir ein Video verfügbar:
Was nun? Muss ich mich um Inscription Time kümmern?
Aber Petr, du hast immer gepredigt, Inscription Times zu ignorieren — warum schreibst du jetzt darüber, wie man sie speichert und auswertet?
Erstens: Ich habe immer angegeben, unter welchen Bedingungen die Inscription Time ignoriert werden kann.
Zweitens: Die meisten von Ihnen sollten die Inscription Time in den meisten Fällen nach wie vor ignorieren.
Drittens: Ich habe meine Datenkarriere im Banking begonnen und verstehe daher die Notwendigkeit solcher Patterns. Gleichzeitig weiß ich, wie komplex der Umgang mit mehreren Zeitlinien werden kann — deshalb habe ich immer versucht, sie wegzulassen, wenn kein Geschäftswert dahintersteckt, und werde das auch weiterhin tun.
Aber mit einer wachsenden Kundenbasis für unsere Datavault Builder Software kamen immer mehr Anfragen nach einer allgemeinen Lösung. Nach langen Design- und Prototyp-Sessions in den vergangenen Monaten kamen wir zu dem Schluss, dass nur der bi-temporale Satellit das Problem sauber löst — und genau das haben wir umgesetzt und in Version 6.3 des Datavault Builder veröffentlicht.
Besonderer Dank gilt Patrick Cuba (Snowpit), Thomas Herzog (allgemeine Idee bi-temporaler Satelliten als spezielle Form von Multi-Active Satellites) und Dirk Lerner (alle seine Dokumente zur Multi-Temporalität).